Info
While i dislike the whole idea around grinding leetcode puzzles as much as possible, i still like the challenge of thinking about a problem and correcting the implementation with a TDD approach.
The third implementation runs with 0ms runtime and 2.1MB memory usage, this beats 100% and 100% of all solutions, source.
The source code for this puzzle can be found here.
This article highlights three different approaches to solving the puzzle 1576.
The puzzle is fairly easy, the expected input is a string made up of lowercase
alphabetical characters, as well as containing a question mark (?). This
character should be replaced with an alphabetical character and should not be
repeated consecutively.
For example:
1"?zs" -> "azs"
2"ubv?w" -> "ubvaw"
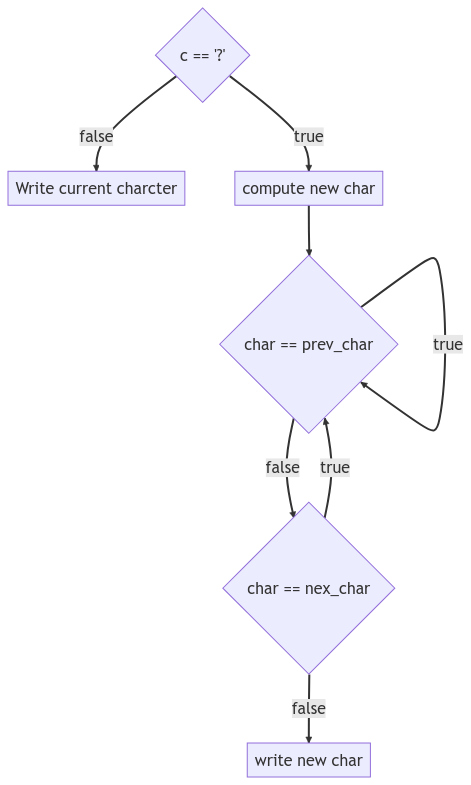
3"j?qg??b" -> "jaqgacb"To implement this, we loop over the characters, check if the current character
is a question mark, choose the a as a replacement, check if the previous
character is a or the following character is a, if so we move on to the
next character.
The logic in the loop can be visualized via a flow chart:
Setup
We already have three test cases taken from the leetcode puzzle, so lets create the skeleton for running our implementation:
1// main.go
2package main
3
4import (
5 "fmt"
6)
7
8var i = []string{
9 "?zs",
10 "ubv?w",
11 "j?qg??b",
12}
13
14func modifyString(s string) string {
15 return ""
16}
17
18func main() {
19 for _, s := range i {
20 fmt.Printf("%s -> %s\n", s, modifyString(s))
21 }
22}First implementation
Our first implementation is straight forward. We define a string to perform a character lookup on.
1// ...
2const alphabet = "abcdefghijklmnopqrstuvwxyz"
3
4func modifyString(s string) string {
5 b := strings.Builder{}
6 for i, r := range s {
7 if r == '?' {
8 rr := 0
9 for (b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1]) ||
10 (len(s) > i+1 && alphabet[rr] == s[i+1]) {
11 rr++
12 }
13 b.WriteByte(alphabet[rr])
14 } else {
15 b.WriteRune(r)
16 }
17 }
18 return b.String()
19}
20// ...We then create a strings.Builder in the function body, which is an incredibly faster way to concatenate strings than simply adding them together (s += "test").
The next step is to iterate of the given string s and checking if the current rune (r) is a question mark.
1// ...
2for i, r := range s {
3 if r == '?'{ /* ...*/ }
4}
5// ...In the else statement, we simply write the current rune to the string builder b.
1// ...
2b := strings.Builder{}
3for i, r := range s {
4 if r == '?'{
5 /* ...*/
6 } else {
7 b.WriteRune(r)
8 }
9}
10// ...To calculate a new character we define a new variable rr which we will use to index the alphabet constant, as well as a for loop to iterate over possible characters.
1// ...
2b := strings.Builder{}
3for i, r := range s {
4 if r == '?'{
5 rr := 0
6 for (b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1]) ||
7 (len(s) > i+1 && alphabet[rr] == s[i+1]) {
8 }
9 } else {
10 b.WriteRune(r)
11 }
12}
13// ...The heart of this approach is the for loop condition inside of the if statement, so lets take this apart:
1(b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1])
2||
3(len(s) > i+1 && alphabet[rr] == s[i+1])Our for loops iterates as long as one of the conditions is met.
1(b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1])
2||
3(len(s) > i+1 && alphabet[rr] == s[i+1])The first condition checks if the string builders b length is bigger than 0, because we want to index it with possibly zero if we are at the start of the string s. And after doing so compares the last character in the string build with the currently computed character.
1(b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1])
2 ^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
3 | |
4 | + checks if the last character
5 | in the string builder
6 | is the same as the currently
7 | computed character
8 |
9 + checks if the string builder can be indexedThe second condition does almost the same thing, but instead of checking the previous character it checks the next character.
1(b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1])
2||
3(len(s) > i+1 && alphabet[rr] == s[i+1])We again start of by checking if the length of the input string is longer than the number we want to index, if true, check if the currently computed character matches the next character in the input string.
1(len(s) > i+1 && alphabet[rr] == s[i+1])
2 ^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^
3 | |
4 | + compare the computed
5 | rune to the next
6 | rune in the input
7 |
8 + check if the string is long enough
9 for us to index the next characterBoth of these conditions rely on lazy evaluation, otherwise indexing the string builder would throw an error.
In the for loop body, we simply increment the alphabet index by one. After computing the new character, we write it to the string builder via a lookup on the alphabet string constant.
1// ...
2 b := strings.Builder{}
3 for i, r := range s {
4 if r == '?' {
5 rr := 0
6 for (b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1]) ||
7 (len(s) > i+1 && alphabet[rr] == s[i+1]) {
8 rr++
9 }
10 b.WriteByte(alphabet[rr])
11 } else {
12 b.WriteRune(r)
13 }
14 }
15}
16// ...At the very end of the implementation, we return the string builders .String() method:
1// ...
2func modifyString(s string) string {
3 b := strings.Builder{}
4 for i, r := range s {
5 if r == '?' {
6 rr := 0
7 for (b.Len() > 0 && alphabet[rr] == b.String()[b.Len()-1]) ||
8 (len(s) > i+1 && alphabet[rr] == s[i+1]) {
9 rr++
10 }
11 b.WriteByte(alphabet[rr])
12 } else {
13 b.WriteRune(r)
14 }
15 }
16 return b.String()
17}
18// ...Running our application via go run main.go, yields the following result:
1go run .
2# ?zs -> azs
3# ubv?w -> ubvaw
4# j?qg??b -> jaqgacbTip
We have some obvious performance issues in this version of the code:
- using a string to lookup characters
- calling len functions multiple times
- computing values in the loop, which could be precomputed
Second implementation
1func modifyStringSecond(s string) string {
2 b := strings.Builder{}
3 for i, r := range s {
4 if r == '?' {
5 rr := 0
6 for (b.Len() > 0 && rr+97 == int(b.String()[b.Len()-1])) ||
7 (len(s) > i+1 && rr+97 == int(s[i+1])) {
8 rr++
9 }
10 b.WriteRune(rune(rr + 97))
11 } else {
12 b.WriteRune(r)
13 }
14 }
15 return b.String()
16}This approach differs from the first approach, by replacing the lookup of a character from the alphabet by adding an offset to the current character.
Due to the fact, that we start our computation of the character we want to replace the question mark with, we can add 97 to this value.
This works, because the lowercase a is located at the Decimal value 97 in the ascii standard.
Go uses UTF-8 for encoding runes / characters, which is ascii compatible and does therefore support our idea.
For example:
Suppose we have the value 10 stored in
rr. Comparing this value to the previous or next character can be done by simply adding 97 to this value.GO1fmt.Println(10+97 == int('k')) 2// true 3fmt.Println(0+97 == int('a')) 4// true 5fmt.Println(1+97 == int('a')) 6// false
Simply removing the character lookup via index of the alphabet constant and replacing this with adding an offset to the computed value should increase the performance right? - as it turns out that is not the case 🤣
Tip
We have some obvious performance issues in this version of the code:
- 3 type conversions per iteration
- computing functions in the loop, which could be precomputed
Third implementation
The third and heavly optimized version decreases the time taken for every operation by a factor of 2 compared to the first implementation.
1func modifyStringThird(s string) string {
2 ls := len(s)
3 b := make([]byte, 0)
4 // input loop
5 for i, r := range s {
6 by := byte(r)
7 lb := len(b)
8 if r == '?' {
9 var rr byte
10 // rune computation loop
11 for (lb > 0 && rr+97 == b[lb-1]) ||
12 (ls > i+1 && rr+97 == s[i+1]) {
13 rr++
14 }
15 by = rr + 97
16 }
17 b = append(b, by)
18 }
19 return string(b)
20}This version uses the optimization we already applied in the second approach (offset instead of rune lookup) plus computing the length of the input and the byte array outside of the rune computing loop.
This approach reduces the type conversions inside of the computing loop from 3
to 0, and inside the input loop to 1. It also does not call any functions
inside the computation loop, such as the strings.Builder.Len() or the
len(s) methods.
Upate
Forth implementation
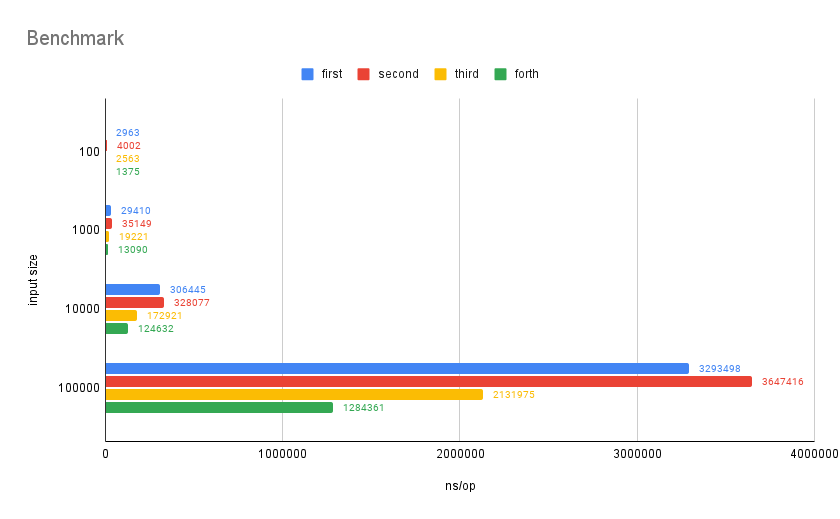
The forth implementation differs from the third in omitting a cast and a function call in the top level loop by moving the byte cast to the loop definition, as well as assigning the result to the byte array at the current index instead of appending to it. This halves the ns/op the third implementation needs to execute the same operation.
1func modifyString(s string) string {
2 ls := len(s)
3 b := make([]byte, ls)
4 for i, r := range []byte(s) {
5 if r == '?' {
6 var rr byte
7 for (i > 0 && rr+97 == b[i-1])
8 || (ls > i+1 && rr+97 == s[i+1]) {
9 rr++
10 }
11 r = rr + 97
12 }
13 b[i] = r
14 }
15 return string(b)
16}Benchmarks
To show the difference between the approaches, i created three benchmarks via the testing framework included in gos std lib:
1package main
2
3import (
4 "strings"
5 "testing"
6)
7
8var inputSizes = map[string]int{
9 "size10": 10,
10 "size100": 100,
11 "size1000": 1000,
12 "size10000": 10000,
13 "size100000": 100000,
14}
15
16func BenchmarkFirst(b *testing.B) {
17 for size, v := range inputSizes {
18 b.Run(size, func(b *testing.B) {
19 for i := 0; i < b.N; i++ {
20 modifyStringFirst(strings.Repeat("j?qg??b", v))
21 }
22 })
23 }
24}
25
26func BenchmarkSecond(b *testing.B) {
27 for size, v := range inputSizes {
28 b.Run(size, func(b *testing.B) {
29 for i := 0; i < b.N; i++ {
30 modifyStringSecond(strings.Repeat("j?qg??b", v))
31 }
32 })
33 }
34}
35
36func BenchmarkThird(b *testing.B) {
37 for size, v := range inputSizes {
38 b.Run(size, func(b *testing.B) {
39 for i := 0; i < b.N; i++ {
40 modifyStringThird(strings.Repeat("j?qg??b", v))
41 }
42 })
43 }
44}Running this via the go test tool, prints interesting results:
1go test ./... -bench=.
2# goos: linux
3# goarch: amd64
4# pkg: leetcode
5# cpu: AMD Ryzen 7 3700X 8-Core Processor
6# BenchmarkFirst/size10-16 2185942 547.2 ns/op
7# BenchmarkFirst/size100-16 337184 3487 ns/op
8# BenchmarkFirst/size1000-16 35896 33587 ns/op
9# BenchmarkFirst/size10000-16 3548 322588 ns/op
10# BenchmarkFirst/size100000-16 352 3424906 ns/op
11
12# BenchmarkSecond/size10-16 1998387 601.3 ns/op
13# BenchmarkSecond/size100-16 298550 3909 ns/op
14# BenchmarkSecond/size1000-16 32400 37335 ns/op
15# BenchmarkSecond/size10000-16 3280 356697 ns/op
16# BenchmarkSecond/size100000-16 318 3777205 ns/op
17
18# BenchmarkThird/size10-16 3076419 393.0 ns/op
19# BenchmarkThird/size100-16 576669 1978 ns/op
20# BenchmarkThird/size1000-16 64304 18599 ns/op
21# BenchmarkThird/size10000-16 7867 156845 ns/op
22# BenchmarkThird/size100000-16 636 1938507 ns/op
23
24# PASS
25# ok leetcode 21.463sComparing the output shows us that the second implementation is a bit slower than the first and the third implementation is around 2x faster than the first implementation:
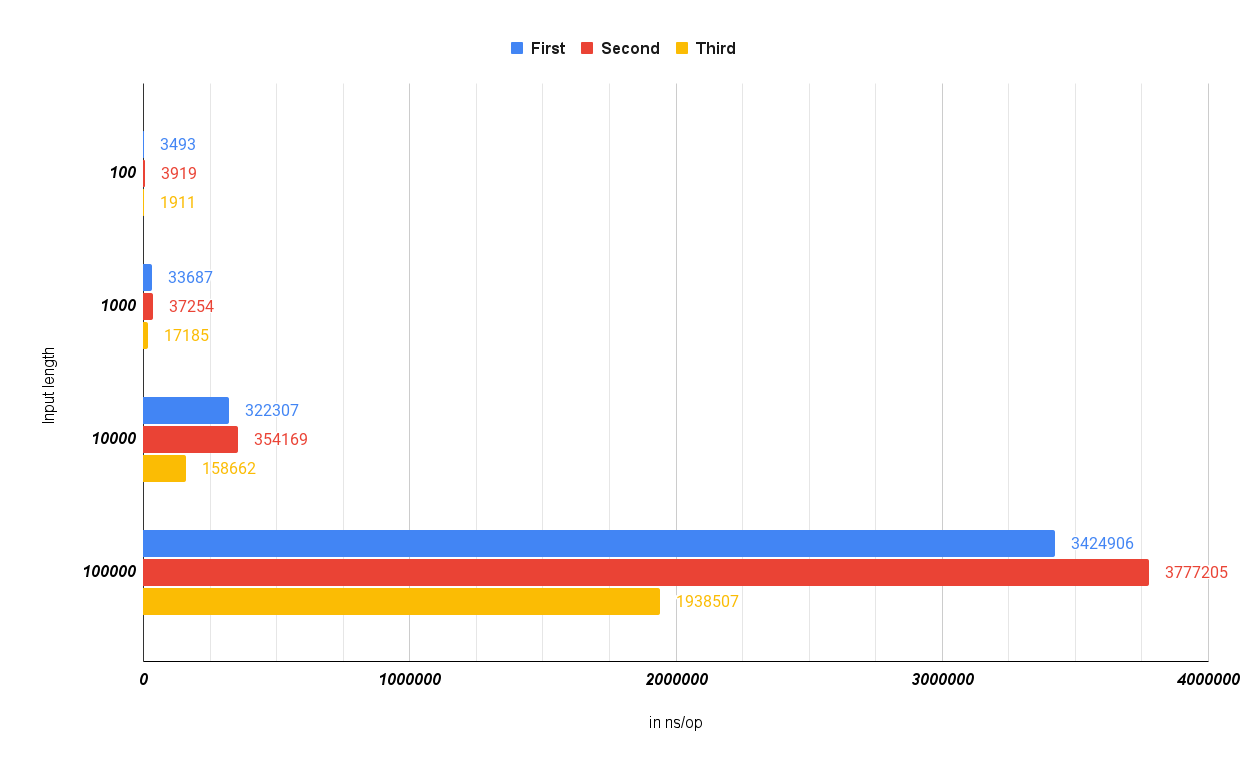
Update
I also added a benchmark for the above function:
1func BenchmarkForth(b *testing.B) {
2 for size, v := range inputSizes {
3 b.Run(size, func(b *testing.B) {
4 for i := 0; i < b.N; i++ {
5 modifyStringForth(strings.Repeat("j?qg??b", v))
6 }
7 })
8 }
9}The updated benchmark, including the forth implementation: