I wrote a json parser in go, because I
wanted to do some language developement, write a lexer and a parser while doing
a lot of performance work. So here i am, almost at the performance of
encoding/json1, but I expose a different way of interacting with
the json object via the xnacly/libjson package
api.
Consider the following example:
1type Structure struct {
2 Field []float64
3}
4var s Structure
5input := []byte(`{ "field": [1, 2]}`)
6if err := json.Unmarshal(input, &s); err != nil {
7 panic(err)
8}
9fmt.Println(s.Field[1])The encoding/json package would use reflection to map JSON key-value pairs to
the correct fields of the structure. I wanted to skip this and just thought to
myself, why not make the access of the JavaScript Object Notation just as we
would with JavaScript - so I did just that, you can be the judge whether it
fits into go.
1obj, err := libjson.New(`{ "field": [1, 2]}`)
2if err != nil {
3 panic(err)
4}
5out, err := libjson.Get[[]float64](obj, ".field")
6if err != nil {
7 panic(err)
8}
9fmt.Println(out)Tip
Please do not mind the toplevel functionlibjson.Get to access values from an
object, go does not support generics for methods of a non generic struct, so I
had to implement it like this.The downside of my implementation is twofold:
- access is slower, because
libjson.Getcomputes the access, whilestruct.fieldis very fast and can be optimised by the go compiler - I plan to implementlibjson.Compileto mitigate this - a second potential error cause, specifically the object access can fail, if the types do not match or the field can not be accessed.
JSONTestSuite Project
I stumbled upon the JSONTestSuite project - the project prides itself with being
A comprehensive test suite for RFC 8259 compliant JSON parsers
So i wanted to test my parser against it, because up until now I simply read
the RFC and decided its easiest to support all floating point integers the
strconv package supports. If i remember correctly, my lexer does not even
support escaping quotes ("). Adding the parser to the project was fairly
easy, see xnacly/JSONTestSuite
a20fc56,
so I ran the suite and was promply surprised with a lot of passing tests and a
lot of tests that were not passing.
Exactly 35 passing and 43 not passing, a good 45% are already passing, thats a good quota. Below an image with all tests that should fail and didn’t.

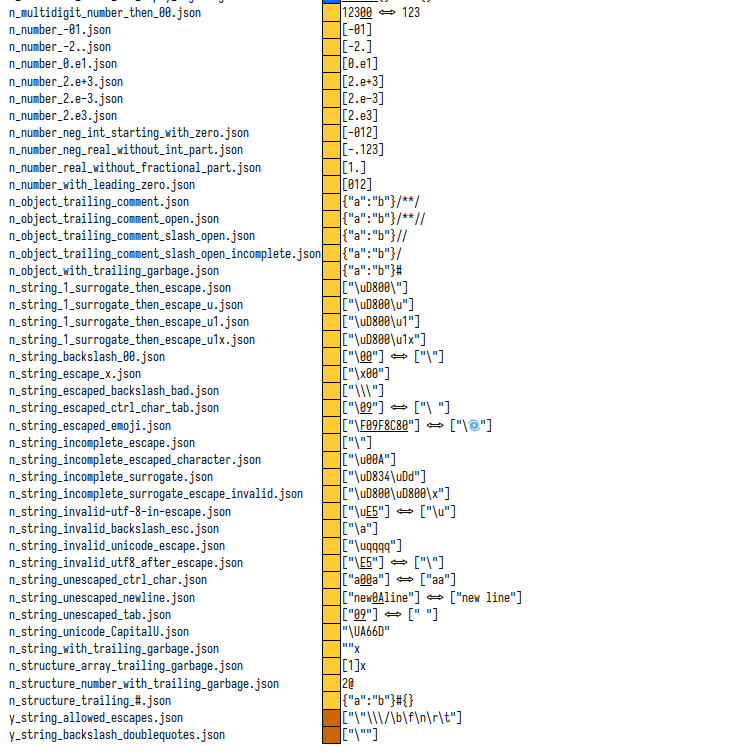
Lets define a test function and work through each and every case:
1func TestStandardFail(t *testing.T) {
2 input := []string{
3 `{"a":"b"}/**/`,
4 }
5 for _, i := range input {
6 t.Run(i, func(t *testing.T) {
7 p := parser{l: lexer{r: bufio.NewReader(strings.NewReader(i))}}
8 _, err := p.parse()
9 assert.Error(t, err)
10 })
11 }
12}libjson has a lot of tests already, thus i will narrow our tests down to only TestStandardFail:
1libjson master M :: go test ./... -run=StandardFail -v
2? github.com/xnacly/libjson/cmd [no test files]
3? github.com/xnacly/libjson/test [no test files]
4=== RUN TestStandardFail
5=== RUN TestStandardFail/{"a":"b"}/**/
6 object_test.go:63:
7 Error Trace: /home/teo/programming/libjson/object_test.go:63
8 Error: An error is expected but got nil.
9 Test: TestStandardFail/{"a":"b"}/**/
10--- FAIL: TestStandardFail (0.00s)
11 --- FAIL: TestStandardFail/{"a":"b"}/**/ (0.00s)
12FAIL
13FAIL github.com/xnacly/libjson 0.002s
14FAILIll append this blog every once in a while if I have time and wil republish it :), below is my first day
Day 1 - Objects and trash
I don’t care about cases with numbers, simply because strconv does my number
parsing. I also will merge similar cases, thus i will start with the first five
comment and thrash tests, and you can read about how I fixed each and every
case:
1func TestStandardFail(t *testing.T) {
2 input := []string{
3 `{"a":"b"}/**/`,
4 `{"a":"b"}/**//`,
5 `{"a":"b"}//`,
6 `{"a":"b"}/`,
7 `{"a":"b"}#`,
8 }
9 for _, i := range input {
10 t.Run(i, func(t *testing.T) {
11 p := parser{l: lexer{r: bufio.NewReader(strings.NewReader(i))}}
12 _, err := p.parse()
13 assert.Error(t, err)
14 })
15 }
16}All of these fail:
1--- FAIL: TestStandardFail (0.00s)
2 --- FAIL: TestStandardFail/{"a":"b"}/**/ (0.00s)
3 --- FAIL: TestStandardFail/{"a":"b"}/**// (0.00s)
4 --- FAIL: TestStandardFail/{"a":"b"}// (0.00s)
5 --- FAIL: TestStandardFail/{"a":"b"}/ (0.00s)
6 --- FAIL: TestStandardFail/{"a":"b"}# (0.00s)
7FAIL
8FAIL github.com/xnacly/libjson 0.002s
9FAILLets figure out why these do not fail, as they should. The first step is to
take a look at the tokens generated by the lexer, for this I simply log them
once the parser requests them in the (*parser).advance() function in the
parser.go file:
1func (p *parser) advance() error {
2 t, err := p.l.next()
3 fmt.Printf("|type=%-6s|value=%-5s|err=%q\n", tokennames[t.Type], string(t.Val), err)
4 p.t = t
5 if p.t.Type == t_eof {
6 return nil
7 }
8 return err
9}tokenname is a hashmap in the types.go file mapping the token types
returned by the lexer to their names, this really helps with debugging, believe
me:
1var tokennames = map[t_json]string{
2 t_string: "string",
3 t_number: "number",
4 t_true: "true",
5 t_false: "false",
6 t_null: "null",
7 t_left_curly: "{",
8 t_right_curly: "}",
9 t_left_braket: "[",
10 t_right_braket: "]",
11 t_comma: ",",
12 t_colon: ":",
13 t_eof: "EOF",
14}Anyways, executing our first test again we can clearly see there are no more tokens requested after the closing curly brace, but there is an error the parser simply not passes up the chain.
1=== RUN TestStandardFail
2=== RUN TestStandardFail/{"a":"b"}/**/
3|type={ |value= |err=%!q(<nil>)
4|type=string|value=a |err=%!q(<nil>)
5|type=: |value= |err=%!q(<nil>)
6|type=string|value=b |err=%!q(<nil>)
7|type=} |value= |err=%!q(<nil>)
8|type=EOF |value= |err="Unexpected character '/' at this position."
9 object_test.go:70:
10 Error Trace: /home/teo/programming/libjson/object_test.go:70
11 Error: An error is expected but got nil.
12 Test: TestStandardFail/{"a":"b"}/**/
13--- FAIL: TestStandardFail (0.00s)
14 --- FAIL: TestStandardFail/{"a":"b"}/**/ (0.00s)
15FAIL
16FAIL github.com/xnacly/libjson 0.002s
17FAILThis is because the (*parser).advance() function returns nil if the token is
t_eof to handle the case of the input ending. We have to add another
condition to this if, specifically add && err != nil to check if the input is
really done or we have an error from the lexer.
1func (p *parser) advance() error {
2 t, err := p.l.next()
3 p.t = t
4 if p.t.Type == t_eof && err != nil {
5 return err
6 }
7 return nil
8}This makes not only the first test pass, but all of them:
1libjson master M :: go test ./... -run=StandardFail -v
2? github.com/xnacly/libjson/cmd [no test files]
3? github.com/xnacly/libjson/test [no test files]
4=== RUN TestStandardFail
5=== RUN TestStandardFail/{"a":"b"}/**/
6=== RUN TestStandardFail/{"a":"b"}/**//
7=== RUN TestStandardFail/{"a":"b"}//
8=== RUN TestStandardFail/{"a":"b"}/
9=== RUN TestStandardFail/{"a":"b"}#
10--- PASS: TestStandardFail (0.00s)
11 --- PASS: TestStandardFail/{"a":"b"}/**/ (0.00s)
12 --- PASS: TestStandardFail/{"a":"b"}/**// (0.00s)
13 --- PASS: TestStandardFail/{"a":"b"}// (0.00s)
14 --- PASS: TestStandardFail/{"a":"b"}/ (0.00s)
15 --- PASS: TestStandardFail/{"a":"b"}# (0.00s)
16PASS
17ok github.com/xnacly/libjson 0.002s1.4ms slower for 1MB inputs, 7.9ms slower for 5MB and 13ms slower for 10MB (on my machine, see Benchmarks) ↩︎