Info
This paper was created in collobaration with daniel0611 as part of the 5th semester as a research project.
The source code for this paper and all code examples can be found in the github repository. The pdf version is accessible here.
All citations are sadly lost due to the translation via pandoc, if you’re interested in them consider checking out the pdf above.
Introduction ##
Garbage collection refers to the process of automatically managing heap allocated memory on behalf of the running process by identifying parts of memory that are no longer needed. This is often performed by the runtime of a programming language while the program is executing.
Most programming languages allocate values with static lifetimes1 in main memory along with the executable code. Values that are alive for a certain scope are allocated using the call stack2 without requiring dynamic allocation. These Variables can’t escape the scope they were defined in and must be dynamically allocated if accessing them outside of their scope is desired.
This requires the programmer to allocate and deallocate these variables to prevent memory leaks3 provided the programming language does not perform garbage collection.
1#include <stdio.h>
2#include <stdlib.h>
3typedef struct {
4 char *name;
5 double age;
6} Person;
7
8Person *new_person(char *name, double age) {
9 Person *p = malloc(sizeof(Person));
10 p->age = age, p->name = name;
11 return p;
12}
13// [...]
Listing
[code:c_heap_alloc_example]
showcases a possible use case for dynamic memory allocation. The
Person structure is filled with values defined in the parameters of
the new_person function. This structure, if stack allocated, would not
live longer than the scope of the new_person function, thus rendering
this function useless. To create and use a Person structure outside of
its scope, the structure has to be dynamically allocated via the
malloc function defined in the #include <stdlib.h> header.
1// [...]
2int main(void) {
3 for(int i = 0; i < 1e5; i++) {
4 Person *p = new_person("max musterman", 89);
5 }
6 return EXIT_SUCCESS;
7}
See listing
[code:c_heap_memory_leak_example]
for an example of a memory leak. Here the program creates $1*10^5$
Person structures using the new_person function allocating each one
on the heap but not releasing their memory after the iteration ends and
therefore rendering the reference to them inaccessible, which generally
defines a memory leakage this programming error can lead to abnormal
system behaviour and excessive RAM consumption in long lived
applications . The definitive solution for memory leaks is determining
leaking variables and freeing them, see listing
[code:c_heap_memory_leak_example_fixed].
1// [...]
2int main(void) {
3 for(int i = 0; i < 1e5; i++) {
4 Person *p = new_person("max musterman", 89);
5 free(p);
6 }
7 return EXIT_SUCCESS;
8}
Another potential issue with manual memory management is accessing
already released memory classified as use-after-free errors . Consider
the modified example in listing
[code:c_heap_memory_use_after_free_example]
showcasing value access of a Person structure after its memory has
already been released.
1// [...]
2int main(void) {
3 for(int i = 0; i < 1e5; i++) {
4 Person *p = new_person("max musterman", 89);
5 free(p);
6 printf("Person{name: '%s', age: %f}\n", p->name, p->age);
7 }
8 return EXIT_SUCCESS;
9}
The example in listing [code:c_heap_memory_use_after_free_example] results in undefined behaviour and could cause crashes if memory the program can not legally access is accessed, could cause memory corruption if the memory region pointed to contains data after the previous data has been released or could be exploited to inject data into the application .
1// [...]
2void *free_person(Person *p) {
3 free(p);
4 return NULL;
5}
6
7int main(void) {
8 for(int i = 0; i < 1e5; i++) {
9 Person *p = new_person("max musterman", 89);
10 p = free_person(p);
11 if(p == NULL) continue;
12 printf("Person{name: '%s', age: %f}\n", p->name, p->age);
13 }
14 return EXIT_SUCCESS;
15}
A common resolution for this issue is setting a pointer to NULL via
p = NULL and checking if the pointer is NULL before accessing it
(see listing [code:c_heap_memory_use_after_free_example_fixed])
.
Garbage collection manages dynamically allocated memory for the
programmer, therefore issues such as memory leakages and accessing
released memory can be prevented by not exposing capabilities for manual
memory management. A language such as golang contains a garbage
collector enabling automatically releasing no longer used memory blocks,
as shown in listing
[code:go_heap_alloc_example].
The garbage collector in listing
[code:go_heap_alloc_example]
automatically deallocates the result of new_person upon it leaving the
scope of the loop iteration it was called in.
1package main
2
3import "fmt"
4
5type Person struct {
6 Name string
7 Age float64
8}
9
10func NewPerson(name string, age float64) *Person {
11 return &Person{name, age}
12}
13
14func main() {
15 for i := 0; i < 1e5; i++ {
16 p := NewPerson("max musterman", 89)
17 fmt.Printf("Person{name: %q, age: %f}\n", p.Name, p.Age)
18 }
19}
Garbage Collection ##
As introduced before (see [sec:introduction]) the process of garbage collection is required by many programming languages via their specification, as is the case with Java and Go . The Go programming language specification however does not include specifics around the implementation of its garbage collection . The Go standard tool chain provides a runtime library included in all executables created by the Go compiler. This library contains the garbage collector .
Garbage collection can be implemented using a variety of strategies, each differing in their code complexity, RAM/CPU usage and execution speed .
Garbage collection as a whole is an umbrella term for different concepts, algorithms and ideas. This chapter includes the differentiation between these and thereby introduces terms necessary for understanding the following chapters.
Scope ###
The scope of garbage collection refers to the variables, resources and
memory areas it manages. Garbage collection is generally responsible for
managing already allocated memory, either by the programmer or the
libraries / subroutines the programmer uses . The aforementioned can be
cumulated to heap allocated memory or dynamically allocated memory. This
represents the purview of a garbage collector . The listing
[code:java_gc_variables]
showcases variables that will be garbage collected upon the scope of the
GarbageCollected.main() function ends.
1class Scope {
2 static class Test {
3 }
4
5 public static void main(String[] args) {
6 var test1 = new Scope.Test();
7 var test2 = new Scope.Test();
8 }
9}
The areas not managed by the garbage collector and thus not in the scope
of this paper are open resources requiring being closed by the consumer
(such as sockets or java.util.Scanner ) and stack allocated variables
as well as statically allocated variables. The listing
[code:java_non_gc_variables]
displays a variety of variables not garbage collected due to all of them
being stack allocated primitive types .
1class Scope1 {
2 static int integer = 5;
3
4 public static void main(String[] args) {
5 byte newline = 0x1A;
6 double pi = 3.1415;
7 char a = 'a';
8 }
9}
Tracing ###
Most commonly the term garbage collection is used to refer to tracing garbage collection. This strategy of automatically managing memory is a common way of implementing garbage collection. Tracing is defined as determining which objects should be deallocated. This is done by tracing which of the currently allocated objects are accessible via linked references. Accessible objects are marked as alive. Memory regions not accessible via this list are not marked and therefore considered to be unused memory and are deallocated.
Programming languages such as Java , Go and Ocaml use this strategy for deallocating unused memory regions.
As introduced before the main idea behind tracing garbage collection is to trace the memory set4. Garbage collection is often performed in cycles. Cycles are triggered when certain conditions are met, such as the program running out of memory and therefore not being able to satisfy an allocation request or the cycles are ran on a predefined interval. The process of tracing memory and deallocating memory require separation, they are therefore often split into different garbage collection cycles. The following concepts and implementation details can be and are generally intertwined in modern garbage collectors .
Categorizing memory ####
Objects5 are categorised as reachable or alive if they are referenced
by at least one variable in the currently running program, see
[code:javamemory_categories_example]
for a visualisation. This includes references from other reachable
objects. As introduced before, the definition of tracing garbage
collection includes determining whether or not objects are reachable. In
the paragraph above, this reachability is defined. This definition does
not include the objects the tracing garbage collector refers to as
_root-objects . root-objects are defined as generally accessible, such
as local variables, parameters and global variables.6 Root-objects
are used as a starting point for tracing allocated objects .
In [code:java_memory_categories_example],
both values initially assigned to x and y in the Main.main
function are considered inaccessible due to the reassignment of x and
y in the following lines. The value of the variable z in the
Main.f function is considered inaccessible once the scope of the
function ends, when the variable z is dropped from the call stack -
rendering its value inaccessible.
1public class MemoryCategories {
2 public static void main(String[] args) {
3 var x = new Object();
4 x = new Object();
5 var y = new Object();
6 y = new Object();
7 MemoryCategories.f();
8 }
9
10 private static void f() {
11 var z = new Object();
12 }
13}
Mark and Sweep ####
Garbage collectors using the mark and sweep-concept traverse the object graph7 starting from the root-objects, therefore satisfying the definition of a tracing garbage collector, as presented in [sec:categorizingmemory]. The main detail of the mark and sweep technique is marking each encountered object of the object graph as alive. This stage of the process is referred to as _marking. The stage defined as sweeping entails walking over the memory on the heap and deallocating all non marked objects .
Generational ####
Generational garbage collection is based on the empirical observation that recently allocated objects are most likely to be inaccessible quickly8. Objects are differentiated into generations, this is often implemented by using separate memory regions for different generations. Upon filling a generations memory region its objects are being traced by using the older generation as roots, this usually results in most objects of the generation being deallocated. The remaining objects are moved into the older generations memory region . This technique results in fast incremental garbage collection, considering one memory region at a time is required to be collected.
Stop the world ####
Stop the world garbage collector refer to the process of halting the execution of the program for running a garbage collection cycle. Therefore guaranteeing that no new objects are allocated or becoming unreachable while performing the garbage collection cycle. The main advantage of this implementation approach is that it introduces less code complexity while being faster than the previously introduced incremental garbage collection . This technique is inherently unsuited for applications requiring real-time performance, such as games or web servers in which unexpected latency has drastic results.
Reference Counting ###
Reference counting garbage collection is defined as each object keeping
track of the amount of references made to it. This reference counter is
incremented for each created reference and decremented for each
destroyed reference. Once the counter reaches 0 the object is no longer
considered reachable and therefore deallocated .
In contrast to the previously introduced tracing garbage collection this
approach promises that objects are immediately deallocated once their
last reference is destroyed. Due to the reference count being attached
to their respective objects this strategy is CPU cache friendly .
Reference counting garbage collection has several disadvantages to the aforementioned tracing garbage collection. These can be mitigated via sophisticated algorithms. The following chapters highlight a selection of problems commonly occurring when implementing reference counting garbage collection .
Memory usage ####
Reference counting requires attaching a reference counter onto allocated objects, thus increasing the overall memory footprint proportionally to the amount of allocated objects and a reference counter for each object.
$$ \begin{align} n &:= \textrm{Amount of Objects}\\ m &:= \textrm{Object size} \\ r &:= \textrm{Reference counter size} \end{align} $$
Memory footprint without reference counting:
$$ \begin{equation} n \cdot m \end{equation} $$
Memory footprint with reference counting:
$$ \begin{equation} nm + nr \end{equation} $$
Cycles ####
Two or more objects creating references to each other is described as a reference cycle. This results in none of the objects being categorised as garbage as their collective references never let their reference count decrement to 0.
A way to prevent reference cycles is by extending reference counting garbage collection to specifically detecting cycles, as is the case in CPython .
Increment and Decrement Workload ####
Each reference creation and reference falling out of scope requires modification of the reference count of one or more objects . There are methods for decreasing this workload, such as ignoring stack references to objects until they are about to be deallocated, triggering a stack scan for making sure the object is no longer referenced or merging reference counter modifications .
Thread safety ####
Reference counting garbage collection requires atomic operations in multithreaded environments to keep a consistent count of references. This requires expensive overhead and is often mitigated with a reference counter per thread. This solution introduces significant memory overhead and is not commonly used .
Escape Analysis ###
The term escape analysis describes a compile-time technique for determining where to store an object, either on the heap or the stack. At a high-level the analysis determines whether an allocated object is reachable outside of its current scope. If so the object is said to escape to the heap. Otherwise the object is allocated on the stack and as previously introduced deallocated/dropped once the scope ends. . Due to the omitted cost of managing the short lived allocated objects not used outside of their scope, the workload of the garbage collector is reduced significantly .
1type T struct { x int64 }
2
3func A() *T {
4 return &T{x:12}
5}
6
7func B() {
8 t := &T{x:25}; t.x++
9}
In [code:go_escape_analysis]
the allocated structure of type *T in function A escapes to the heap
due to the fact that it is returned from A. The structure assigned to
t of type *T in B is dropped upon the t.x++ instruction is
executed and the scope of B ends. The Go compiler allocates the value
of t on the stack - a direct result of escape analysis .
Comparison with other Memory Management Techniques ##
In this section alternatives to garbage collection for memory management are presented and compared to garbage collection.
Manual Memory Management ###
Manual memory management is the most basic memory management technique.
It is used in languages like C and C++. In this technique the programmer
is responsible for allocating and freeing memory. This is done by
calling the malloc and free functions in C and the new and
delete operators in C++. The programmer has to keep track of the
allocated memory and free it when it is no longer needed. This is done
by storing the pointer returned by the allocation function in a variable
and passing it to the free function when it is no longer needed. This is
illustrated in [code:c_manual_memory_management_example].
1int main() {
2 // Allocate memory for a single integer
3 int* a = malloc(sizeof(int));
4 *a = 42;
5
6 // Allocate memory for an array of 10 integers
7 int* b = malloc(sizeof(int) * 10);
8 for (int i = 0; i < 10; i++) {
9 b[i] = i;
10 }
11
12 // Free the allocated memory
13 free(a);
14 free(b);
15}
This technique is very error prone and can lead to memory leaks and use-after-free errors resulting in undefined behaviour and security vulnerabilities as explained in [sec:introduction]. However it is usually the fastest memory management technique because it does not have any overhead compared to garbage collection.
Lifetimes and Borrow Checking ###
The desire for the performance of manual memory management and the
safety of garbage collection has led to the development of a new memory
management technique called lifetimes and borrow checking. The main
idea behind this technique is that the corresponding free calls for
heap memory can be automatically inserted at compile time by the
compiler, if the compiler can prove that the memory is no longer needed.
When a variable is no longer needed, it is said to have reached the end
of its lifetime hence the name of the technique.
Because this is run at compile-time the performance is similar to manual memory management. The safety is comparable to garbage collection because the compiler can prove that there are no use-after-free errors or memory leaks when compiling, assuming the compiler is correct. While this technique has the best-of-both-worlds properties of manual memory management and garbage collection for safety and performance, it lacks in ease-of-use because the programmer has to follow a set of rules. Satifying these rules can be difficult and can take sometimes take a time, especially for beginners
This memory management technique in the presented form was first introduced in the Rust programming language replacing the garbage collector it initially had . Because Rust was the first language to implement this concept, the examples in this section will be written in Rust.
Ownership ####
The first step to understand this technique is to understand the concept of ownership.
In Rust, every value is always owned by exactly a variable inside a scope. When the variable goes out of scope, the value is dropped. The ownership of a value can be transferred to another variable by moving it. This can be either in the form of an assignment or as a function return value. When a value is moved, the previous owner can no longer access the value. When a value is dropped by going out of scope, any memory it owns is freed, including heap memory .
A major contrast in Rust compared to other programming languages like C
is that variable assignments like let a = b are moving the value
instead of copying it . The same goes for the parameter values for
function calls. Because of this variables can not be used after being
used in a variable assignment or function call.
A example showcasing the ownership concept similar 9 to the C example presented in the introduction can be found in [code:rust_ownership_person_example] 10.
1struct Person {
2 name: String,
3 age: f64,
4}
5
6fn new_person(name: String, age: f64) -> Person {
7 Person { name, age }
8}
9
10fn print_person(person: Person) {
11 println!("{} is {} years old.", person.name, person.age);
12}
13
14fn main() {
15 let person = new_person("Rainer Zufall".into(), 42.0);
16 let person1 = person; // value of person is moved to person1
17 // print_person(person); // error: use of moved value: `person`
18 print_person(person1);
19
20 { // Example of sub-scope
21 let person2 = new_person("Jona Zufall".into(), 13.0);
22 print_person(person2);
23 } // person2 is dropped here
24} // person1 and person are dropped here
Borrowing ####
The second step to understand this technique is to understand the concept of borrowing. Allowing only one owner to access a variable at a time would be too restrictive for many uses cases.
As a example calling the print_person function twice on the same
person would not be possible, because the ownership of the person would
be moved to the function after the first call and cannot be accessed
anymore. This is illustrated in
[code:rust_person_double_print].
1let person = new_person("Rainer Zufall".into(), 42.0);
2print_person(person);
3print_person(person); // error: use of moved value: `person`
The solution to this problem is the concept of borrowing. It essentially is the pointer concept from C and other languages but with the ownership model of Rust in mind, which imposes some restrictions on it. Borrowing allows a value owner to give another function or struct access to a value without giving ownership to the function . A owner can hand out many read-only borrows to a value at the same time, but only one mutable borrow at a time. This is done to avoid data races but is not strictly needed for the memory management aspect of the technique .
A modified version of the presented person example to make use of borrows can be found in [code:rust_borrow_person_example].
1fn print_person(person: &Person) {
2 println!("{} is {} years old.", person.name, person.age);
3}
4
5fn main() {
6 let person = new_person("Rainer Zufall".into(), 42.0);
7 print_person(&person); // borrow using &
8 print_person(&person); // borrow a second time
9} // person is dropped here
A borrow can only be used as long as the owner is still alive. A borrow can not outlive the owner variable. This is enforced at compile time using the borrow checker. Through this free-after-use errors can be detected at compile time. This also means that the timepoint in program execution when a heap allocated value is no longer needed is always when the owner variable lifetime ends because there cannot be any borrows to the value after that point .
Multi-owner values using reference counters ####
Some usecases require a value to be owned by multiple owners at the same time. These usecases include shared memory and cyclic data structures.
Allowing multiple owners for a single value can be done by using
reference counters as a escape hatch. A reference counter is a data
structure that keeps track of the number of owners of a value and drops
the value when the number of owners reaches zero. This is done by
incrementing the counter when a new owner is created using .clone()
and decrementing it when a owner is dropped. Reference counter
implementations are available in the Rust standard library as
std::rc::Rc<T> and std::sync::Arc<T> for single threaded and atomic
multi-threaded use respectively. An example of this can be found in
[code:rust_ref_counter_example].
1use std::rc::Rc;
2
3fn main() {
4 // Create an Rc that contains a person
5 let person = Rc::new(new_person("Rainer Zufall".into(), 42.0));
6
7 // Clone the Rc to create additional references
8 // These can be moved to other owners and outlive the original Rc instance
9 let clone1 = Rc::clone(&person);
10 let clone2 = Rc::clone(&person);
11
12 println!("Reference count of person: {}", Rc::strong_count(&person));
13
14 // Access the data through the cloned references
15 println!("clone1 data: {:?}", clone1);
16 println!("clone2 data: {:?}", clone2);
17
18 // When the references go out of scope, the reference count decreases
19 drop(clone1);
20 println!("Count after dropping clone1: {}", Rc::strong_count(&person));
21
22 drop(clone2);
23 println!("Count after dropping clone2: {}", Rc::strong_count(&person));
24
25 // At this point, the reference count drops to zero, and the memory is
26 // deallocated because the last reference is dropped.
27}
28
29// output:
30// Reference count of person: 3
31// clone1 data: Person { name: "Rainer Zufall", age: 42.0 }
32// clone2 data: Person { name: "Rainer Zufall", age: 42.0 }
33// Count after dropping clone1: 2
34// Count after dropping clone2: 1
The cloned reference counter instance can be moved to other owners and outlive the original instance. This works great for non-cyclic data structures, but not so well by itself for cyclic data structures (see [sec:reference_counting_cycles]) because the reference counter will never reach zero and the memory will never be freed. To solve this problem, you can use weak references or break the cycle manually when you are done with the data structure. When the developer does not deal with this problem a memory leak will occur.
Garbage collected Programming Languages ##
In this chapter, garbage collection implementations of two programming languages are presented. Both make use of the theoretical concepts presented in [sec:overview].
Go ###
Go uses a tri-color, concurrent mark & sweep garbage collector based on an algorithm introduced by Dijkstra in 1978 . The go compiler employs escape analysis for reducing the amount of heap allocated objects at compile time (see [sec:escapeanalysis]). Mark & sweep garbage collection introduces the requirement of tracing all memory before any memory can be released for there could still be untraced pointers marking an object previously thought to be unreachable as reachable. This segments the gc cycles into _marking and sweeping while also introducing the off phase notating the garbage collector as inactive while no GC related work is required.
Detecting reachable objects ####
As the name suggests and introduced in [sec:gcmark_sweep], the go garbage collector determines whether or not an object is to be considered reachable by starting from the root objects (see [sec:categorizing_memory]) and scanning all following pointers and objects - this process is defined as the _mark stage of the mark & sweep algorithm.
As previously introduced, the employed algorithm for archiving this in an efficient way is based upon the previous work by Dijkstra. This approach revolves around three sets: the white set - all candidates for having their memory recycled, the black set - all objects without references to the white set and that are reachable from the roots, the grey set - objects reachable from the roots not yet scanned for references to the white objects. Considering this assumption, the algorithm considers all objects as white at the start of the given garbage collection cycle and starts the following process:
An object from the grey set is picked.
Each white object the current object references is moved to the grey set (neither the object nor all referenced objects can be garbage collected)
The current object is moved to the black set.
Repeat previous steps until the grey set is empty.
This algorithm has the advantage of allowing “on-the-fly” garbage collection without halting the whole system for long time periods, therefore reducing the latency typically imposed onto systems by garbage collection . This is implemented by marking objects as soon as they are allocated and during their mutation, thus maintaining the previously introduced sets. The garbage collector can monitor the set sizes and clean up periodically, instead of doing so as soon as its required. This approach allows for skipping the scan of the whole allocated heap on each garbage collection cycle .
Fine-tuning ####
The go garbage collector can be tweaked to fine-tune the trade-off
between the garbage collectors CPU and memory usage . This can be done
by invoking the go runtime with an environment variable called GOGC .
The go garbage collector tries to finish a collection cycle before the current total heap size is bigger than the target heap size.
$$\textrm{Target heap memory} = \textrm{Live heap} + \left(\textrm{Live heap} + \textrm{GC roots}\right) \cdot \textrm{GOGC} / 100$$
For the given values of a live heap size of 8 MiB11, 1 MiB of
goroutine stacks, 1 MiB of pointers in global variables and a value of
100 for the GOGC environment variable the equation results in:
$$ \begin{align} \textrm{Target heap memory} &= 8 \ \textrm{MiB} + \left(8 \ \textrm{MiB} + 1 \ \textrm{MiB}\right) \cdot 100 / 100 \\ &= 17 \ \textrm{MiB} \end{align} $$
This formula allows for a precise garbage collection cycle trigger, such
as running a garbage collection cycle once the specific threshold of
newly allocated memory, here the 10 MiB cumulated from the 8 MiB live
heap, 1 MiB goroutine stack and 1 MiB global variables. The GOGC
variable controls this threshold. A value of 100 signals the garbage
collector to switch into the marking stage once 100% of the size of
previous live heap is allocated since the last garbage collection cycle,
a value of 50 halves the threshold from 10 MiB to 5 MiB, the value 200
doubles the threshold to 20 MiB .
Java ###
Java by default uses a generational garbage collector as introduced in [sec:gc_generational]. This garbage collector is called Garbage First (G1) and was made the default with Java 9 . Before that, Java used various types of mark and sweep collectors .
Beyond those there are many more garbage collectors available for Java that can be used by specifying them as a command line argument to the JVM. These are not relevant for this writing, as they are not used by default. Nonetheless these can be very useful when wanting to use a garbage collector tuned to a specific use case.
Garbage First Collector introduction ####
Contrary to the theoretical concept of a generational garbage collector introduced in [sec:gc_generational], the memory areas for each generation in G1GC are not continuous in memory. Instead G1GC uses a heap divided into regions usually 1 MB - 32 MB in size. Each region is assigned to one of the generations or unused. These generations are called Eden, Survivor and Old. An example heap layout with regions assigned to the generations is shown in [fig:g1_heap_layout].
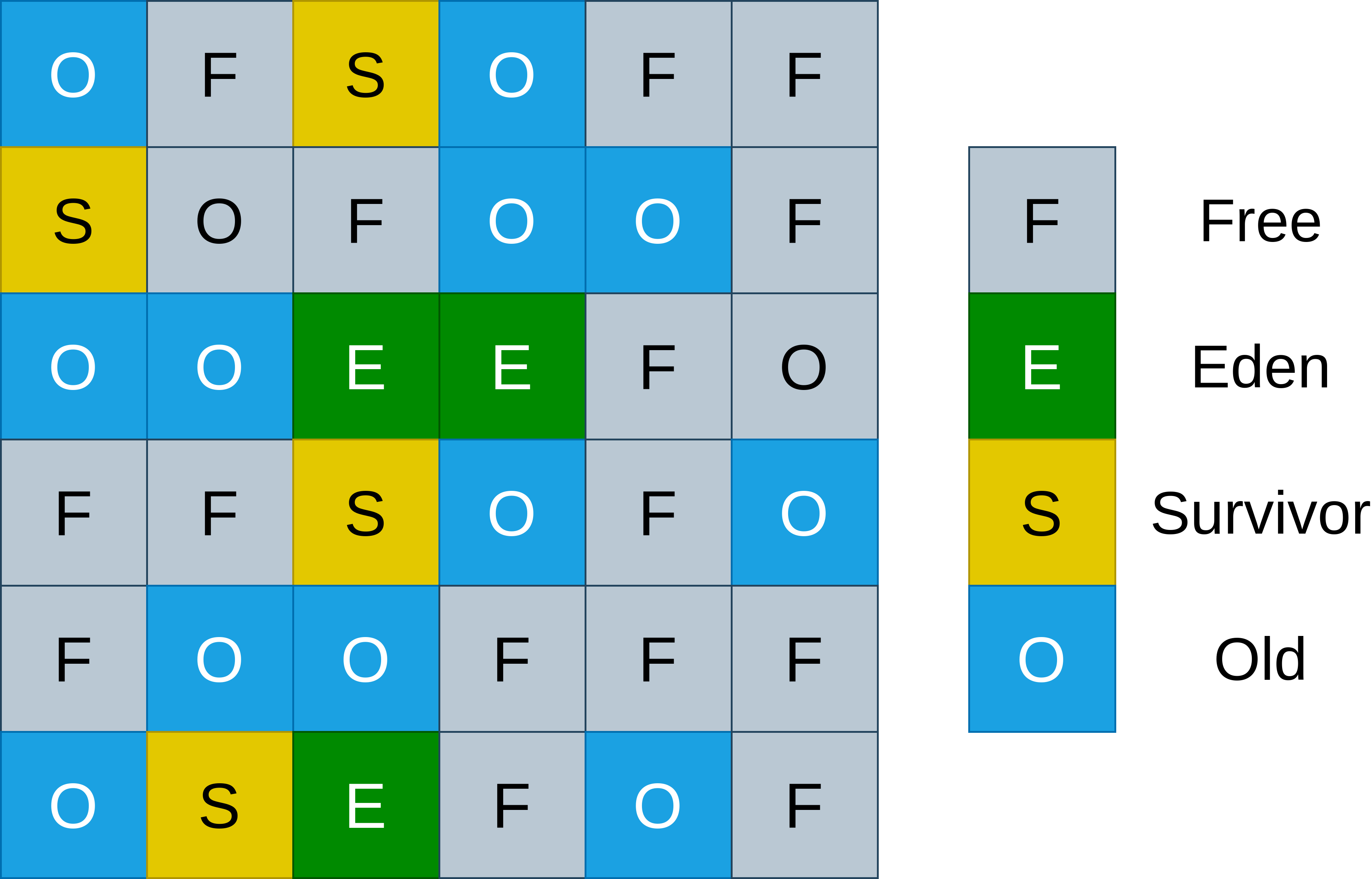
Using constant sized regions instead of continuous memory areas has the advantage that the heap does not need to be contiguous in memory for generational garbage collection to work.
Allocating memory to new objects ####
When a object is allocated onto the heap, it will be first allocated into the Eden region inside of the Young generation as outlined in the theoretical concept of generational garbage collection in [sec:gc_generational]. One memory region is marked as the current allocation region. New objects are allocated into this region until. Once the region is full, it will be marked as full and a new currently unused region will be chosen as the new allocation region . If no free memory region is available, a new one will be allocated through the operating system.
Large objects are stored in their own regions, called humongous regions and not inside the Young/Old generation regions. This is done to simplify the garbage collection of large objects which would cause problems when stored inside the Young/Old generation regions .
Collecting memory from memory regions ####
Garbage collection is done in two phases, like outlayed in [sec:gc_tracing]. For G1 these phases work a bit differently because of the split heap into constant size regions.
Marking #####
When garbage collection is triggered G1 first needs to determine which memory regions are not referenced by any live objects anymore. To do this G1 uses a concurrent marking algorithm that uses snapshot-at-the-beginning . To ensure memory consistency during the marking phase, G1 uses a write barrier to save write operations to a log. The changes of this log are applied in the final phase of the marking phase which will stop-the-world to apply the log changes to the heap and retrace anything that might have changed during the marking phase .
From the traced memory regions, G1 will then select regions to collect. This is done by estimating the amount of garbage in each heap memory region using the marking step results. Regions with more garbage will be prioritized for collection over regions with less garbage, because collecting regions with more garbage will result in more memory being freed for less work.
Evacuation #####
After deciding which regions to collect, G1 will start the evacuation phase. In this phase, G1 will copy all live objects from the selected regions to other regions. This can be either a new memory region or one that is only partly filled. After copying all live objects, the old memory regions will be freed resulting in the unused memory regions being freed. Objects will be copied to regions of the same generation as the region they were copied from or one generation older, if the objects are old enough. The objects are copied sequentially into the new region without any gaps between them, resulting in a compacted memory region.
Realtime goal of G1 ####
G1 tries have low pause times for garbage collection improving the responsiveness of the application and allow for usage in applications requiring predictable pause times. However pause times are only goals, and there are no guarantees that they will be met.
It does this by estimating the amount of garbage in each region and prioritizing regions with more garbage for collection, resulting in lower stop-the-world mark phases compared to regions with less garbage. Additionally it predicts how long a collection of a region will take and limit the amount that is done in a garbage collection cycle to meet a specified time goal.
The pause time goal and desired intervals for garbgage collection pauses can be configured using JVM command line arguments.
Conclusion ##
In this paper, we have explored the concept and techniques of garbage collection, a process of automatically reclaiming heap allocated memory that is no longer in use by the program. We have reviewed various garbage collection strategies, such as reference counting and tracing with mark & sweep and generational garbage collection, and analyzed their trade-offs in terms of code complexity, memory usage, CPU overhead, and execution speed.
We also have compared garbage collection with other memory management techniques, such as manual memory management and the lifetimes & borrow checking concept from Rust. The performance, safety, and ease-of-use of these techniques were evaluated and the challenges and opportunities they pose for software development were discussed. Manual memory management is fast but error prone and can lead to memory leaks and use-after-free errors. Lifetimes and borrow checking is safe and fast but requires the programmer to adhere to a set of rules that can be difficult to satisfy. Garbage collection is safe and easy to use but introduces some overhead and latency.
Furthermore, we have presented the garbage collection implementations of two programming languages: Go and Java. We have described how Go uses a tri-color, concurrent mark & sweep garbage collector based on an algorithm by Dijkstra, and how it employs escape analysis to reduce the amount of heap allocated objects. We have also explained how Java uses a generational garbage collector called Garbage First (G1) that divides the heap into constant sized regions and prioritizes regions with more garbage for collection.
Garbage collection is a fascinating and important topic in computer science and programming languages. It has a significant impact on the performance, reliability, and usability of software systems. As memory demands and concurrency levels increase, garbage collection techniques will need to evolve and adapt to meet the challenges and opportunities of the future.
variable available for the whole runtime of the program ↩︎
stores information about running subroutines / functions ↩︎
allocated no longer needed memory not deallocated ↩︎
Virtual memory the program makes use of ↩︎
Dynamically allocated memory region containing one or more values ↩︎
As introduced in [sec:scope]: variables on the call stack or static variables ↩︎
Objects and pointers to objects ↩︎
Generally known as infant mortality or generational hypothesis ↩︎
The presented Rust example differs from the C example because the
create_personfunction does not return a reference but a value. However the struct consists of aStringwhich is a heap allocated dynamic length string that gets allocated by the.into()call converting the static&strintoString, so the example still requires the used heap memory to be freed. References/Borrows to temporary values are not allowed in Rust so the only way to force a heap allocation of the whole struct would be to use astd::boxed::Box<T>. This was not used in this example for legibility reasons. ↩︎A more idomatic Rust implementation would define the new and print functions as methods of the Person struct. This was not done here to keep the example simple for readers not familiar with Rust. ↩︎
MiB: 1024 Kibibytes ↩︎