I am currently writing a analysis tool for Sql:
sqleibniz, specifically for the sqlite dialect.The goal is to perform static analysis for sql input, including: syntax checks, checks if tables, columns and functions exist. Combining this with an embedded sqlite runtime and the ability to assert conditions in this runtime, creates a really great dev experience for sql.
Furthermore, I want to be able to show the user high quality error messages with context, explainations and the ability to mute certain diagnostics.
This analysis includes the stages of lexical analysis/tokenisation, the parsing of SQL according to the sqlite documentation1 and the analysis of the resulting constructs.
After completing the static analysis part of the project, I plan on writing a lsp server for sql, so stay tuned for that.
In the process of the above, I need to write a tokenizer and a parser - both for SQL. While I am nowhere near completion of sqleibniz, I still made some discoveries around rust and the handy features the language provides for developing said software.
Macros
Macros work different in most languages. However they are used for mostly the same reasons: code deduplication and less repetition.
Abstract Syntax Tree Nodes
A node for a statement in sqleibniz implementation is defined as follows:
1
2#[derive(Debug)]
3/// holds all literal types, such as strings, numbers, etc.
4pub struct Literal {
5 pub t: Token,
6}Furthermore all nodes are required to implement the Node-trait, this trait
is returned by all parser functions and is later used to analyse the contents
of a statement:
1pub trait Node: std::fmt::Debug {
2 fn token(&self) -> &Token;
3}Tip
std::fmt::Debug is used as a super trait for the
Node-trait here, see Using Supertraits to Require One Trait’s Functionality
Within Another
Trait
TLDR:
using a super trait enables us to only allow implementations of the Node
trait if the type already satisfies the std::fmt::Debug trait.
Code duplication
Thus every node not only has to be defined, but an implementation for the
Node-trait has to be written. This requires a lot of code duplication and
rust has a solution for that.
I want a macro that is able to:
- define a structure with a given identifier and a doc comment
- add arbitrary fields to the structure
- satisfying the
Nodetrait by implementingfn token(&self) -> &Token
Lets take a look at the full code I need the macro to produce for the
Literal and the Explain nodes. While the first one has no further fields
except the Token field t, the second node requires a child field with a
type.
1#[derive(Debug)]
2/// holds all literal types, such as strings, numbers, etc.
3pub struct Literal {
4 /// predefined for all structures defined with the node! macro
5 pub t: Token,
6}
7impl Node for Literal {
8 fn token(&self) -> &Token {
9 &self.t
10 }
11}
12
13
14#[derive(Debug)]
15/// Explain stmt, see: https://www.sqlite.org/lang_explain.html
16pub struct Explain {
17 /// predefined for all structures defined with the node! macro
18 pub t: Token,
19 pub child: Option<Box<dyn Node>>,
20}
21impl Node for Explain {
22 fn token(&self) -> &Token {
23 &self.t
24 }
25}I want the above to be generated from the following two calls:
1node!(
2 Literal,
3 "holds all literal types, such as strings, numbers, etc.",
4);
5node!(
6 Explain,
7 "Explain stmt, see: https://www.sqlite.org/lang_explain.html",
8 child: Option<Box<dyn Node>>,
9);Code deduplication with macros
The macro for that is fairly easy, even if the rust macro docs arent that good:
1macro_rules! node {
2 ($node_name:ident,$documentation:literal,$($field_name:ident:$field_type:ty),*) => {
3 #[derive(Debug)]
4 #[doc = $documentation]
5 pub struct $node_name {
6 /// predefined for all structures defined with the node! macro, holds the token of the ast node
7 pub t: Token,
8 $(
9 pub $field_name: $field_type,
10 )*
11 }
12 impl Node for $node_name {
13 fn token(&self) -> &Token {
14 &self.t
15 }
16 }
17 };
18}Lets disect this macro. The Macro argument/metavariable definition starts with
$node_name:ident,$documentation:literal:
1$node_name : ident , $documentation : literal
2^^^^^^^^^^ ^ ^^^^^ ^
3| | | |
4| | | metavariable delimiter
5| | |
6| | metavariable type
7| |
8| metavariable type delimiter
9|
10metavariable nameMeaning, we define the first metavariable of the macro to be a valid identifier rust accepts and the second argument to be a literal. A literal refers to a literal expression, such as chars, strings or raw strings.
Tip
For theliteral and the ident meta variable types, see Literal
expressions
and Identifiers. For
the whole metavariable type reference, see
Metavariables.The tricky part that took me some time to grasp is the way of defining
repetition of metavariables in macros, specifically $($field_name:ident:$field_type:ty),*.
1$($field_name:ident:$field_type:ty),*
2^^ ^ ^ ^
3| | | |
4| metavariable | repetition
5| delimiter | (any)
6| |
7 sub group of metavariablesAs I understand, we define a subgroup in our metavarible definition and
postfix it with its repetition. We use : to delimit inside the metavariable
sub-group, this enables us to write the macro in a convienient field_name: type way:
1node!(
2 Example,
3 "Example docs",
4
5 // sub group start
6 field_name: &'static str,
7 field_name1: String
8 // sub group end
9);We can use the $(...)* syntax to “loop over” our sub grouped metavariables,
and thus create all fields with their respective names and types:
1pub struct $node_name {
2 pub t: Token,
3 $(
4 pub $field_name: $field_type,
5 )*
6}Tip
See Repetitions for the metavariable repetition documentation.Remember: the $documentation metavariable holds a literal containing our doc
string we want to generate for our node - we now use the #[doc = ...]
annotation instead of the commonly known /// ... syntax to pass our macro
metavariable to the compiler:
1#[doc = $documentation]
2pub struct $node_name {
3 // ...
4}I’d say the trait implementation for each node is pretty self explanatory.
Testing
Lets start off with me saying: I love table driven tests and the way Go allows to write them:
1func TestLexerWhitespace(t *testing.T) {
2 cases := []string{"","\t", "\r\n", " "}
3 for _, c := range cases {
4 t.Run(c, func (t *testing.T) {
5 l := Lexer{}
6 l.init(c)
7 l.run()
8 })
9 }
10}In Go, I define an array of cases and just execute a test function for each
case c. As far as I know, Rust does not offer a similar test method - so
made one 😼.
Lexer / Tokenizer Tests
1#[cfg(test)]
2mod should_pass {
3 test_group_pass_assert! {
4 string,
5 string: "'text'"=vec![Type::String(String::from("text"))],
6 empty_string: "''"=vec![Type::String(String::from(""))],
7 string_with_ending: "'str';"=vec![Type::String(String::from("str")), Type::Semicolon]
8 }
9
10 // ...
11}
12
13#[cfg(test)]
14mod should_fail {
15 test_group_fail! {
16 empty_input,
17 empty: "",
18 empty_with_escaped: "\\",
19 empty_with_space: " \t\n\r"
20 }
21
22 // ...
23}Executing these via cargo test, results in the same output I love from table
driven tests in Go, each function having its own log and feedback
(ok/fail):
1running 68 tests
2test lexer::tests::should_pass::string::empty_string ... ok
3test lexer::tests::should_pass::string::string ... ok
4test lexer::tests::should_pass::string::string_with_ending ... ok
5test lexer::tests::should_fail::empty_input::empty ... ok
6test lexer::tests::should_fail::empty_input::empty_with_escaped ... ok
7test lexer::tests::should_fail::empty_input::empty_with_space ... ok
8
9test result: ok. 68 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out;
10finished in 0.00sThe macro accepts the name of the test group, for example: booleans and
string and a list of input and expected output pairs. The input is passed to
the Lexer initialisation and the output of the Lexer.run() is compared
against the expected output. Inlining the test_group_pass_assert! call for
string results in the code below. Before asserting the equality of the
resulting token types and the expected token types, a transformation is
necessary, I map over the token vector and only return their types.
1mod string {
2 use crate::{lexer, types::Type};
3
4 #[test]
5 fn string() {
6 let input = "'text'".as_bytes().to_vec();
7 let mut l = lexer::Lexer::new(&input, "lexer_tests_pass");
8 let toks = l.run();
9 assert_eq!(l.errors.len(), 0);
10 assert_eq!(
11 toks.into_iter().map(|tok| tok.ttype).collect::<Vec<Type>>(),
12 (vec![Type::String(String::from("text"))])
13 );
14 }
15
16 #[test]
17 fn empty_string() {
18 let input = "''".as_bytes().to_vec();
19 let mut l = lexer::Lexer::new(&input, "lexer_tests_pass");
20 let toks = l.run();
21 assert_eq!(l.errors.len(), 0);
22 assert_eq!(
23 toks.into_iter().map(|tok| tok.ttype).collect::<Vec<Type>>(),
24 (vec![Type::String(String::from(""))])
25 );
26 }
27
28 #[test]
29 fn string_with_ending() {
30 let input = "'str';".as_bytes().to_vec();
31 let mut l = lexer::Lexer::new(&input, "lexer_tests_pass");
32 let toks = l.run();
33 assert_eq!(l.errors.len(), 0);
34 assert_eq!(
35 toks.into_iter().map(|tok| tok.ttype).collect::<Vec<Type>>(),
36 (vec![Type::String(String::from("str")), Type::Semicolon])
37 );
38 }
39}The counter part test_group_fail! for empty_input! produces the code below.
The main difference being the assertion of the resulting token vector to be
empty and the Lexer.errors field to contain at least on error.
1mod empty_input {
2 use crate::lexer;
3
4 #[test]
5 fn empty() {
6 let source = "".as_bytes().to_vec();
7 let mut l = lexer::Lexer::new(&source, "lexer_tests_fail");
8 let toks = l.run();
9 assert_eq!(toks.len(), 0);
10 assert_ne!(l.errors.len(), 0);
11 }
12
13 #[test]
14 fn empty_with_escaped() {
15 let source = "\\".as_bytes().to_vec();
16 let mut l = lexer::Lexer::new(&source, "lexer_tests_fail");
17 let toks = l.run();
18 assert_eq!(toks.len(), 0);
19 assert_ne!(l.errors.len(), 0);
20 }
21
22 #[test]
23 fn empty_with_space() {
24 let source = " \t\n\r".as_bytes().to_vec();
25 let mut l = lexer::Lexer::new(&source, "lexer_tests_fail");
26 let toks = l.run();
27 assert_eq!(toks.len(), 0);
28 assert_ne!(l.errors.len(), 0);
29 }
30}Lets take a look at the macros itself, I will not go into detail around the
macro definition - simply because I explained the meta variable declaration in
the previous chapter. The first macro is
uesd for the assertions of test with valid inputs - test_group_pass_assert!:
1macro_rules! test_group_pass_assert {
2 ($group_name:ident,$($ident:ident:$input:literal=$expected:expr),*) => {
3 mod $group_name {
4 use crate::{lexer, types::Type};
5
6 $(
7 #[test]
8 fn $ident() {
9 let input = $input.as_bytes().to_vec();
10 let mut l = lexer::Lexer::new(&input, "lexer_tests_pass");
11 let toks = l.run();
12 assert_eq!(l.errors.len(), 0);
13 assert_eq!(toks.into_iter().map(|tok| tok.ttype).collect::<Vec<Type>>(), $expected);
14 }
15 )*
16 }
17 };
18}While the second is used for invalid inputs and edge case testing with expected
errors - test_group_fail!:
1macro_rules! test_group_fail {
2 ($group_name:ident,$($name:ident:$value:literal),*) => {
3 mod $group_name {
4 use crate::lexer;
5 $(
6 #[test]
7 fn $name() {
8 let source = $value.as_bytes().to_vec();
9 let mut l = lexer::Lexer::new(&source, "lexer_tests_fail");
10 let toks = l.run();
11 assert_eq!(toks.len(), 0);
12 assert_ne!(l.errors.len(), 0);
13 }
14 )*
15 }
16 };
17}Parser Tests
I use the same concepts and almost the same macros in the parser module to
test the results the parser produces, but this time focussing on edge cases and
full sql statements. For instance the tests expected to pass and to fail for
the EXPLAIN sql statement:
1#[cfg(test)]
2mod should_pass {
3 test_group_pass_assert! {
4 sql_stmt_prefix,
5 explain: r#"EXPLAIN VACUUM;"#=vec![Type::Keyword(Keyword::EXPLAIN)],
6 explain_query_plan: r#"EXPLAIN QUERY PLAN VACUUM;"#=vec![Type::Keyword(Keyword::EXPLAIN)]
7 }
8}
9
10#[cfg(test)]
11mod should_fail {
12 test_group_fail! {
13 sql_stmt_prefix,
14 explain: r#"EXPLAIN;"#,
15 explain_query_plan: r#"EXPLAIN QUERY PLAN;"#
16 }
17}Both macros get the sql_stmt_prefix as their module names, because thats the
function, in the parser, responsible for the EXPLAIN statement. The failing
tests check wheter the parser correctly asserts the conditions the sql standard
lays out, see sqlite - sql-stmt.
Specifically, either that a statement follows after the EXPLAIN identifier or
the QUERY PLAN and a statement follow.
The difference between these tests and the tests for the lexer are in the way the assertions are made. Take a look at the code the macros produce:
1#[cfg(test)]
2mod should_pass {
3 mod sql_stmt_prefix {
4 use crate::{lexer, parser::Parser, types::Keyword, types::Type};
5
6 #[test]
7 fn explain() {
8 let input = r#"EXPLAIN VACUUM;"#.as_bytes().to_vec();
9 let mut l = lexer::Lexer::new(&input, "parser_test_pass");
10 let toks = l.run();
11 assert_eq!(l.errors.len(), 0);
12 let mut parser = Parser::new(toks, "parser_test_pass");
13 let ast = parser.parse();
14 assert_eq!(parser.errors.len(), 0);
15 assert_eq!(
16 ast.into_iter()
17 .map(|o| o.unwrap().token().ttype.clone())
18 .collect::<Vec<Type>>(),
19 (vec![Type::Keyword(Keyword::EXPLAIN)])
20 );
21 }
22
23 #[test]
24 fn explain_query_plan() {
25 let input = r#"EXPLAIN QUERY PLAN VACUUM;"#.as_bytes().to_vec();
26 let mut l = lexer::Lexer::new(&input, "parser_test_pass");
27 let toks = l.run();
28 assert_eq!(l.errors.len(), 0);
29 let mut parser = Parser::new(toks, "parser_test_pass");
30 let ast = parser.parse();
31 assert_eq!(parser.errors.len(), 0);
32 assert_eq!(
33 ast.into_iter()
34 .map(|o| o.unwrap().token().ttype.clone())
35 .collect::<Vec<Type>>(),
36 (vec![Type::Keyword(Keyword::EXPLAIN)])
37 );
38 }
39 }
40}As shown, the test_group_pass_assert! macro in the parser module starts
with the same Lexer initialisation and empty error vector assertion. However,
the next step is to initialise the Parser structure and after parsing assert
the outcome - i.e. no errors and nodes with the correct types.
1#[cfg(test)]
2mod should_fail {
3 mod sql_stmt_prefix {
4 use crate::{lexer, parser::Parser};
5 #[test]
6 fn explain() {
7 let input = r#"EXPLAIN;"#.as_bytes().to_vec();
8 let mut l = lexer::Lexer::new(&input, "parser_test_fail");
9 let toks = l.run();
10 assert_eq!(l.errors.len(), 0);
11 let mut parser = Parser::new(toks, "parser_test_fail");
12 let _ = parser.parse();
13 assert_ne!(parser.errors.len(), 0);
14 }
15
16 #[test]
17 fn explain_query_plan() {
18 let input = r#"EXPLAIN QUERY PLAN;"#.as_bytes().to_vec();
19 let mut l = lexer::Lexer::new(&input, "parser_test_fail");
20 let toks = l.run();
21 assert_eq!(l.errors.len(), 0);
22 let mut parser = Parser::new(toks, "parser_test_fail");
23 let _ = parser.parse();
24 assert_ne!(parser.errors.len(), 0);
25 }
26 }
27}The test_group_fail! macro also extends the same macro from the lexer
module and appends the check for errors after parsing. Both macro_rules!:
1macro_rules! test_group_pass_assert {
2 ($group_name:ident,$($ident:ident:$input:literal=$expected:expr),*) => {
3 mod $group_name {
4 use crate::{lexer, parser::Parser, types::Type, types::Keyword};
5 $(
6 #[test]
7 fn $ident() {
8 let input = $input.as_bytes().to_vec();
9 let mut l = lexer::Lexer::new(&input, "parser_test_pass");
10 let toks = l.run();
11 assert_eq!(l.errors.len(), 0);
12
13 let mut parser = Parser::new(toks, "parser_test_pass");
14 let ast = parser.parse();
15 assert_eq!(parser.errors.len(), 0);
16 assert_eq!(ast.into_iter()
17 .map(|o| o.unwrap().token().ttype.clone())
18 .collect::<Vec<Type>>(), $expected);
19 }
20 )*
21 }
22 };
23}
24
25macro_rules! test_group_fail {
26 ($group_name:ident,$($ident:ident:$input:literal),*) => {
27 mod $group_name {
28 use crate::{lexer, parser::Parser};
29 $(
30 #[test]
31 fn $ident() {
32 let input = $input.as_bytes().to_vec();
33 let mut l = lexer::Lexer::new(&input, "parser_test_fail");
34 let toks = l.run();
35 assert_eq!(l.errors.len(), 0);
36
37 let mut parser = Parser::new(toks, "parser_test_fail");
38 let _ = parser.parse();
39 assert_ne!(parser.errors.len(), 0);
40 }
41 )*
42 }
43 };
44}Macro Pitfalls
rust-analyzerplays badly insidemacro_rules!- no real intellisense
- no goto definition
- no hover for signatures of literals and language constructs
cargo fmtdoes not format or indent inside ofmacro_rules!and macro invokationstreesitter(yes I use neovim, btw 😼) andchroma(used on this site) sometimes struggle with syntax highlighting ofmacro_rules!- documentation is sparse at best
Matching Characters
When writing a lexer, comparing characters is the part everything else depends
on. Rust makes this enjoyable via the matches! macro and the patterns the
match statement accepts. For instance, checking if the current character is
a valid sqlite number can be done by a simple matches! macro invocation:
1/// Specifically matches https://www.sqlite.org/syntax/numeric-literal.html
2fn is_sqlite_num(&self) -> bool {
3 matches!(self.cur(),
4 // exponent notation with +-
5 '+' | '-' |
6 // sqlite allows for separating numbers by _
7 '_' |
8 // floating point
9 '.' |
10 // hexadecimal
11 'a'..='f' | 'A'..='F' |
12 // decimal
13 '0'..='9')
14}Similarly testing for identifiers is as easy as the above:
1fn is_ident(&self, c: char) -> bool {
2 matches!(c, 'a'..='z' | 'A'..='Z' | '_' | '0'..='9')
3}Symbol detection in the main loop of the lexer works exactly the same:
1pub fn run(&mut self) -> Vec<Token> {
2 let mut r = vec![];
3 while !self.is_eof() {
4 match self.cur() {
5 // skipping whitespace
6 '\t' | '\r' | ' ' | '\n' => {}
7 '*' => r.push(self.single(Type::Asteriks)),
8 ';' => r.push(self.single(Type::Semicolon)),
9 ',' => r.push(self.single(Type::Comma)),
10 '%' => r.push(self.single(Type::Percent)),
11 _ => {
12 // omitted error handling for unknown symbols
13 panic!("whoops");
14 }
15 }
16 self.advance();
17 }
18 r
19}Patterns in match statement and matches blocks are arguably the most
useful feature of Rust.
Matching Tokens
Once the lexer converts the character stream into a stream of Token structure
instances with positional and type information, the parser can consume this
stream and produce an abstract syntax tree. The parser has to recognise
patterns in its input by detecting token types. This again is a case where
Rusts match statement shines.
Each Token contains a t field for its type, see below.
1pub use self::keyword::Keyword;
2
3#[derive(Debug, PartialEq, Clone)]
4pub enum Type {
5 Keyword(keyword::Keyword),
6 Ident(String),
7 Number(f64),
8 String(String),
9 Blob(Vec<u8>),
10 Boolean(bool),
11 ParamName(String),
12 Param(usize),
13
14 Dot,
15 Asteriks,
16 Semicolon,
17 Percent,
18 Comma,
19
20 Eof,
21}Lets look at the sql_stmt_prefix method of the parser. This function parses
the EXPLAIN statement, which - according to the sqlite documentation -
prefixes all other sql statements, hence the name. The corresponding syntax
diagram is shown below:

The implementation follows this diagram. The Explain stmt is optional, thus
if the current token type does not match Type::Keyword(Keyword::EXPLAIN), we
call the sql_stmt function to processes the statements on the right of
the syntax diagram.
If the token matches it gets consumed and the next check is for the second
possible path in the EXPLAIN diagram: QUERY PLAN. This requires both the
QUERY and the PLAN keywords consecutively - both are consumed.
1impl<'a> Parser<'a> {
2 fn sql_stmt_prefix(&mut self) -> Option<Box<dyn Node>> {
3 match self.cur()?.ttype {
4 Type::Keyword(Keyword::EXPLAIN) => {
5 let mut e = Explain {
6 t: self.cur()?.clone(),
7 child: None,
8 };
9 self.advance(); // skip EXPLAIN
10
11 // path for EXPLAIN->QUERY->PLAN
12 if self.is(Type::Keyword(Keyword::QUERY)) {
13 self.consume(Type::Keyword(Keyword::QUERY));
14 self.consume(Type::Keyword(Keyword::PLAN));
15 } // else path is EXPLAIN->*_stmt
16
17 e.child = self.sql_stmt();
18 Some(Box::new(e))
19 }
20 _ => self.sql_stmt(),
21 }
22 }
23}This shows the basic usage of pattern matching in the parser. An other
example is the literal_value function, its sole purpose is to create the
Literal node for all literals.
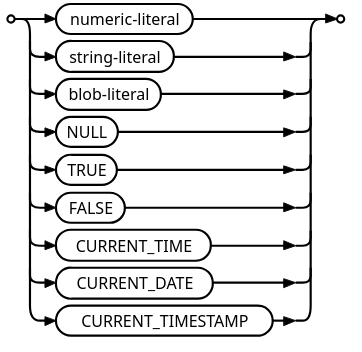
It discards most embedded enum values, but checks for some specific keywords, because they are considered keywords, while being literals:
1impl<'a> Parser<'a> {
2 /// see: https://www.sqlite.org/syntax/literal-value.html
3 fn literal_value(&mut self) -> Option<Box<dyn Node>> {
4 let cur = self.cur()?;
5 match cur.ttype {
6 Type::String(_)
7 | Type::Number(_)
8 | Type::Blob(_)
9 | Type::Keyword(Keyword::NULL)
10 | Type::Boolean(_)
11 | Type::Keyword(Keyword::CURRENT_TIME)
12 | Type::Keyword(Keyword::CURRENT_DATE)
13 | Type::Keyword(Keyword::CURRENT_TIMESTAMP) => {
14 let s: Option<Box<dyn Node>> = Some(Box::new(Literal { t: cur.clone() }));
15 self.advance();
16 s
17 }
18 _ => {
19 // omitted error handling for invalid literals
20 panic!("whoops");
21 }
22 }
23 }
24}Fancy error display
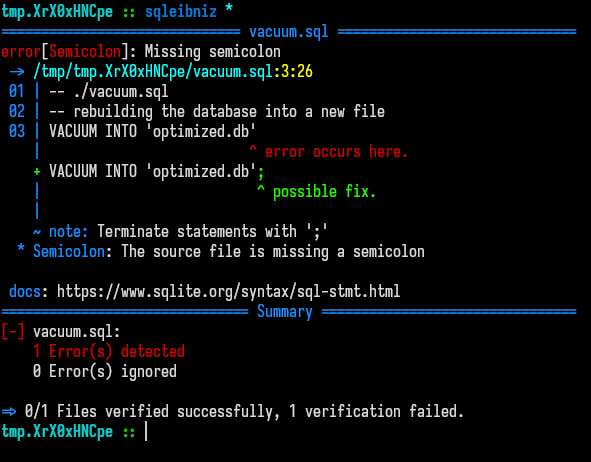
While the implementation itself is repetitive and not that interesting, I still wanted to showcase the way both the lexer and the parser handle errors and how these errors are displayed to the user. A typical error would be to miss a semicolon at the end of a sql statement:
SQL1-- ./vacuum.sql 2-- rebuilding the database into a new file 3VACUUM INTO 'optimized.db'Passing this file to
sqleibnizpromptly errors:
Optionals
Rust error handling is fun to do and propagation with the ?-Operator just
makes sense. But Rust goes even further, not only can I modify the value inside
of the Option if there is one, I can even check conditions or provide default
values.
is_some_and
Sometimes you simply need to check if the next character of the input stream
is available and passes a predicate. is_some_and exists for this reason:
1fn next_is(&mut self, c: char) -> bool {
2 self.source
3 .get(self.pos + 1)
4 .is_some_and(|cc| *cc == c as u8)
5}
6
7fn is(&self, c: char) -> bool {
8 self.source.get(self.pos).is_some_and(|cc| *cc as char == c)
9}The above is really nice to read, the following not so much:
1fn next_is(&mut self, c: char) -> bool {
2 match self.source.get(self.pos + 1) {
3 Some(cc) => *cc == c as u8,
4 _ => false,
5 }
6}
7
8fn is(&self, c: char) -> bool {
9 match self.source.get(self.pos) {
10 Some(cc) => *cc as char == c,
11 _ => false,
12 }
13}map
Since the input is a Vector of u8, not a Vector of char, this conversion is done with map:
1fn next(&self) -> Option<char> {
2 self.source.get(self.pos + 1).map(|c| *c as char)
3}Instead of unwrapping and rewrapping the updated value:
1fn next(&self) -> Option<char> {
2 match self.source.get(self.pos + 1) {
3 Some(c) => Some(*c as char),
4 _ => None,
5 }
6}map_or
In a similar fashion, the sqleibniz parser uses map_or to return
the check for a type, but only if the current token is Some:
1fn next_is(&self, t: Type) -> bool {
2 self.tokens
3 .get(self.pos + 1)
4 .map_or(false, |tok| tok.ttype == t)
5}
6
7fn is(&self, t: Type) -> bool {
8 self.cur().map_or(false, |tok| tok.ttype == t)
9}Again, replacing the not so idiomatic solutions:
1fn next_is(&self, t: Type) -> bool {
2 match self.tokens.get(self.pos + 1) {
3 None => false,
4 Some(token) => token.ttype == t,
5 }
6}
7
8fn is(&self, t: Type) -> bool {
9 if let Some(tt) = self.cur() {
10 return tt.ttype == t;
11 }
12 false
13}Iterators 💖
Filtering characters
Rust number parsing does not allow _, sqlite number parsing
accepts _, thus the lexer also consumes them, but filters these
characters before parsing the input via the rust number parsing
logic:
1let str = self
2 .source
3 .get(start..self.pos)
4 .unwrap_or_default()
5 .iter()
6 .map(|c| *c as char)
7 .filter(|c| *c != '_')
8 .collect::<String>();Tip
I know you aren’t supposed to useunwrap and all derivates,
however in this situation the parser either way does not accept
empty strings as valid numbers, thus it will fail either way on
the default value.In go i would have to first iterate the character list with a for
loop and write each byte into a string buffer (in which each write
could fail btw, or at least can return an error) and afterwards
I have to create a string from the strings.Builder structure.
1s := source[start:l.pos]
2b := strings.Builder{}
3b.Grow(len(s))
4for _, c := range s {
5 if c != '_' {
6 b.WriteByte(c)
7 }
8}
9s = b.String()Checking characters
Sqlite accepts hexadecimal data as blobs: x'<hex>', to verify
the input is correct, I have to check every character in this
array to be a valid hexadecimal. Furthermore I need positional
information for correct error display, for this I reuse the
self.string() method and use the chars() iterator creating
function and the enumerate function.
1if let Ok(str_tok) = self.string() {
2 if let Type::String(str) = &str_tok.ttype {
3 let mut had_bad_hex = false;
4 for (idx, c) in str.chars().enumerate() {
5 if !c.is_ascii_hexdigit() {
6 // error creation and so on omitted here
7 had_bad_hex = true;
8 break;
9 }
10 }
11 if had_bad_hex {
12 break;
13 }
14
15 // valid hexadecimal data in blob
16 }
17} else {
18 // error handling omitted
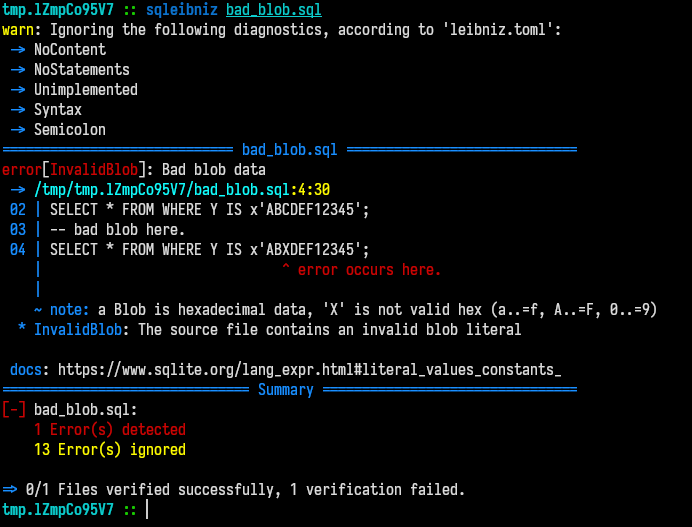
19}The error display produces the following error if an invalid character inside of a blob is found:
Info
Thanks for reading this far 😼.
If you found an error (technical or semantic), please email me a nudge in the
right direction at contact@xnacly.me
(contact@xnacly.me).