TLDR: Info
Porting a segmented list from C to Rust and sharing the process. Both written from scratch and without any dependencies:
1Allocator *a = bump_init(1024, 0);
2LIST_TYPE(size_t);
3LIST_size_t list = LIST_new(size_t);
4size_t count = 64 * 1000 * 1000;
5for (size_t i = 0; i < count; i++) {
6 LIST_append(&list, a, i);
7}
8ASSERT(list.len == count, "list not of correct length");
9CALL(a, destroy);
10free(a);to
1let mut list = SegmentedList::new();
2let count = 64 * 1000 * 1000;
3for i in 0..count {
4 list.push(i);
5}
6assert_eq!(list.len(), count);I needed to replace my growing list of three different dynamic array
implementations in my bytecode interpreter: one for Nodes, one for runtime
Values and one for bytecode. Building the AST and bytecode required a lot of
malloc, realloc and memcpy. I hacked a workaround together by introducing
a segmented bump allocator backed by mmap omitting the syscalls, but memcpy
still remained.
So I wrote (and debugged) a generic segmented list in C unifying those implementations into the following features:
- zero realloc
- zero copy
- lazy allocation on grow
- backed by a bump allocator
I now want to port this to Rust and compare semantics, implementation, performance and how pretty they look.
This isn’t a “C sucks because it’s unsafe and Rust is super duper great because it borrow checks and it’s safe” article, but rather a “I love C but lately I want to use Rust to help me get out of the pain of debugging my lexer, parser and compiler interacting with my segmented bump allocator backed by mmap, my handrolled generic segmented list and everything around that”.
Segmented Lists vs Dynamic Arrays
Vectors suck at growing a lot, because:
- They have to allocate a new and larger block
- They have to copy their contents to the new space
- They require to “update” all references into the previous space to the new space
- For large
mem::size_of::<T>()/sizeof(T), copies are costly and move a lot of memory
On the other hand, segmented lists suck due to:
- The underlying storage being non-contiguous
- Indexing requiring addition, subtraction and bitshifts for finding the segment and its offset
The tradeoff is yours to make. In C benchmarks for large and many AST nodes, segmented lists beat dynamic arrays by 2-4x.
Design
As the name implies, the list consists of segments. Each segment’s size is that of its predecessor multiplied by an implementation-defined growth factor, often 1.5 or 2, this results in geometric growth, reducing the amount of syscalls while growing progressively larger.
The first segment size is also implementation-defined, but often chosen to be 8, a multiple of 2 is, as always, favorable for aligned access and storage. Segments are lazily allocated when they are about to be used. There is no deallocation per element, but rather per segment, at least in this example. The main upside of segmented lists is their zero-copy growth. Other dynamic array implementations often require the previously stored elements to be moved, thus also providing stable pointers.
Indexing
Since a segmented list is based on a group of segments containing its elements,
indexing isn’t as easy as incrementing a pointer by sizeof(T). Instead we
have to compute the segment and the offset for any given index into the list
(\(i\)). Since a list starts with a default size (\(s_0\)) and grows at a
geometric rate (\(\lambda\)). We can compute the segment start with \(S(i)\),
the segment / block index with \(b(i)\) and the offset into said segment with
\(o(i)\):
Therefore, for our segmented list, given \(s_0 := 8\), \(\lambda := 2\) (I use 2, since geometric growth means less syscalls for fast growing lists, the equations hold for \(\lambda > 1\)) and an index \(i := 18\), we can calculate:
$$ \begin{align} b(i) &= \left\lfloor \log_{\lambda} \left( \frac{i}{s_0} + 1 \right) \right\rfloor \\ b(18)&= \left\lfloor \log_{2} \left( \frac{18}{8} + 1 \right) \right\rfloor \\ &= \left\lfloor \log_{2} \left( 3.25 \right) \right\rfloor \\ &= \left\lfloor 1.7004 \right\rfloor \\ &= \underline{1} \\ S(b) &= s_0 \cdot (\lambda^{b} - 1) \\ S(1) &= 8 \cdot (2^{1} - 1) \\ &= \underline{8} \\ o(i) &= i - S(b(i)) \\ o(18)&= 18 - 8 \\ &= \underline{10} \\ \end{align} $$Thus, attempting to index at the position \(18\) requires us to access the segment at position \(1\) with its inner offset of \(10\).
C Implementation
This is my starting point I whipped up in an afternoon. Please keep in mind: this is my first allocator in any sense, I’m still fiddeling around and thusfar asan, valgrind, gcc, clang and my unittests tell me this is fine.
Bump allocator
In purple garden all allocators are based on the Allocator “interface” to
allow for dynamically replacing the bump allocator with different other
allocators, for instance garbage collectors.
1// mem.h
2typedef struct {
3 size_t current;
4 size_t allocated;
5} Stats;
6
7// CALL is used to emulate method calls by calling a METHOD on SELF with
8// SELF->ctx and __VA_ARGS__, this is useful for interface interaction, such as
9// Allocator, which reduces alloc_bump.request(alloc_bump.ctx, 64); to
10// CALL(alloc_bump, request, 64), removing the need for passing the context in
11// manually
12#ifdef VERBOSE_ALLOCATOR
13#include <stdio.h>
14#define CALL(SELF, METHOD, ...) \
15 (fprintf(stderr, "[ALLOCATOR] %s@%s::%d: %s->%s(%s)\n", __FILE__, __func__, \
16 __LINE__, #SELF, #METHOD, #__VA_ARGS__), \
17 (SELF)->METHOD((SELF)->ctx, ##__VA_ARGS__))
18#else
19#define CALL(SELF, METHOD, ...) (SELF)->METHOD((SELF)->ctx, ##__VA_ARGS__)
20#endif
21
22// Allocator defines an interface abstracting different allocators, so the
23// runtime of the virtual machine does not need to know about implementation
24// details, can be used like this:
25//
26//
27// #define ALLOC_HEAP_SIZE = 1024
28// Allocator alloc_bump = bump_init(ALLOC_HEAP_SIZE, ALLOC_HEAP_SIZE*2);
29//
30// size_t some_block_size = 16;
31// void *some_block = alloc_bump.request(alloc_bump.ctx, some_block_size);
32//
33// alloc_bump.destroy(alloc_bump.ctx);
34//
35typedef struct {
36 // Allocator::ctx refers to an internal allocator state and owned memory
37 // areas, for instance, a bump allocator would attach its meta data (current
38 // position, cap, etc) here
39 void *ctx;
40
41 // Allocator::stats is expected to return the current statistics of the
42 // underlying allocator
43 Stats (*stats)(void *ctx);
44 // Allocator::request returns a handle to a block of memory of size `size`
45 void *(*request)(void *ctx, size_t size);
46 // Allocator::destroy cleans state up and deallocates any owned memory areas
47 void (*destroy)(void *ctx);
48} Allocator;
49
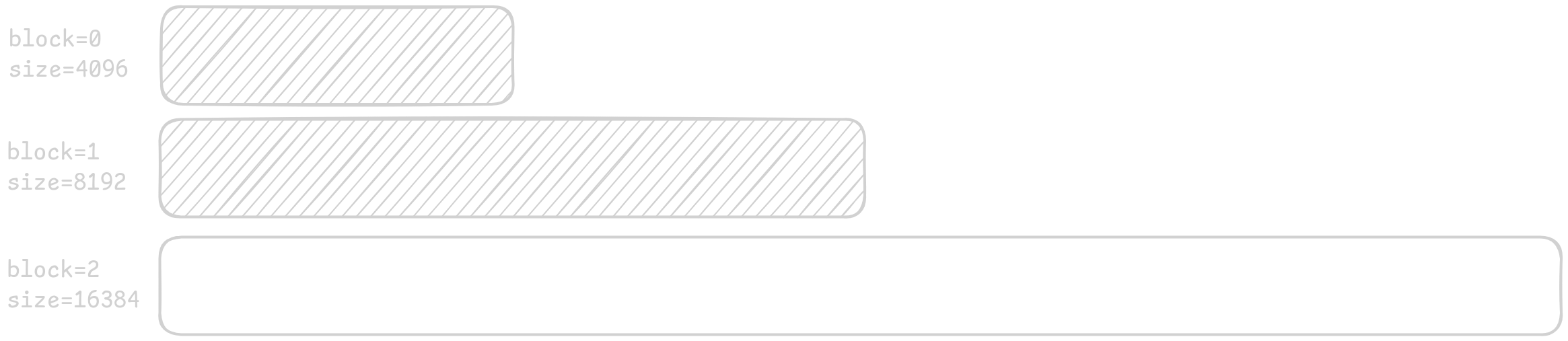
50Allocator *bump_init(uint64_t min_size, uint64_t max_size);The segmented bump allocator itself is of course pretty simple, allocate page aligned block, hand out memory by incrementing the pointer, if out of space in the current block, allocate the next one, as shown for the first three blocks below:
1#define _GNU_SOURCE
2#include "common.h"
3#include "mem.h"
4#include <stdint.h>
5#include <string.h>
6#include <sys/mman.h>
7#include <sys/types.h>
8#include <unistd.h>
9
10#define BUMP_MIN_START 4096
11// geometric series result for max amount of bytes fitting into uint64_t used to
12// count the totally allocated bytes; amounts to something like (2^64)-
13#define BUMP_MAX_BLOCKS 55
14#define BUMP_GROWTH 2
15
16// BumpResize allocator header
17//
18// The bump allocator is implemented as such, so a "regrow" (needing the next
19// block) doesnt invalidate all previously handed out pointers. ALWAYS zero all
20// handed out memory yourself
21typedef struct {
22 // the current block we are in, max is BUMP_MAX_BLOCKS
23 uint64_t pos;
24
25 // the size of the current allocated block
26 uint64_t size;
27
28 // the amount of bytes in the current block in use
29 uint64_t len;
30
31 // the max amount the bump alloc should grow to
32 uint64_t max;
33
34 // kept for Allocator->stats
35 uint64_t total_used;
36 uint64_t total_allocated;
37
38 // List of blocks the bump allocator uses to hand out memory
39 void *blocks[BUMP_MAX_BLOCKS];
40 uint64_t block_sizes[BUMP_MAX_BLOCKS];
41} BumpCtx;
42
43void *bump_request(void *ctx, size_t size) {
44 BumpCtx *b_ctx = ctx;
45 size_t align = sizeof(void *);
46 uint64_t aligned_pos = (b_ctx->len + align - 1) & ~(align - 1);
47
48 if (b_ctx->max > 0) {
49 ASSERT(b_ctx->total_allocated < b_ctx->max,
50 "Bump allocator exceeded max_size");
51 }
52
53 if (aligned_pos + size > b_ctx->size) {
54 ASSERT(b_ctx->pos + 1 < BUMP_MAX_BLOCKS, "Out of block size");
55 uint64_t new_size = b_ctx->size * BUMP_GROWTH;
56
57 void *new_block = mmap(NULL, new_size, PROT_READ | PROT_WRITE,
58 MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
59 ASSERT(new_block != MAP_FAILED, "Failed to mmap new block");
60
61 b_ctx->blocks[++b_ctx->pos] = new_block;
62 b_ctx->block_sizes[b_ctx->pos] = new_size;
63 b_ctx->size = new_size;
64 b_ctx->len = 0;
65 aligned_pos = 0;
66 b_ctx->total_allocated += new_size;
67 }
68
69 void *ptr = (char *)b_ctx->blocks[b_ctx->pos] + aligned_pos;
70 b_ctx->total_used += (aligned_pos - b_ctx->len) + size;
71 b_ctx->len = aligned_pos + size;
72 return ptr;
73}
74
75Allocator *bump_init(uint64_t min_size, uint64_t max_size) {
76 BumpCtx *ctx = malloc(sizeof(BumpCtx));
77 ASSERT(ctx != NULL, "failed to bump allocator context");
78 *ctx = (BumpCtx){0};
79 ctx->size = min_size < BUMP_MIN_START ? BUMP_MIN_START : min_size;
80 ctx->max = max_size;
81 void *first_block = mmap(NULL, ctx->size, PROT_READ | PROT_WRITE,
82 MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
83 ASSERT(first_block != MAP_FAILED, "Failed to mmap initial block");
84 ctx->blocks[0] = first_block;
85 ctx->total_allocated = ctx->size;
86
87 Allocator *a = malloc(sizeof(Allocator));
88 ASSERT(a != NULL, "failed to alloc bump allocator");
89 *a = (Allocator){0};
90 a->ctx = (void *)ctx;
91 a->destroy = bump_destroy;
92 a->request = bump_request;
93 a->stats = bump_stats;
94
95 return a;
96}Deallocation is done by unmapping each allocated block.
1void bump_destroy(void *ctx) {
2 ASSERT(ctx != NULL, "bump_destroy on already destroyed allocator");
3 BumpCtx *b_ctx = (BumpCtx *)ctx;
4 for (size_t i = 0; i <= b_ctx->pos; i++) {
5 if (b_ctx->blocks[i]) {
6 munmap(b_ctx->blocks[i], b_ctx->block_sizes[i]);
7 b_ctx->blocks[i] = NULL;
8 }
9 }
10 free(ctx);
11}With the interface and this implementation all functions in the purple garden
code base that allocate take Allocator *a (or Allocator *alloc) and
requests memory with CALL(a, request, 1024). For instance in the virtual
machine when creating a new space for the globals:
1vm.globals = CALL(alloc, request, (sizeof(Value) * GLOBAL_SIZE));List macros and C “Generics”
My first step was to make use of the macro system to create a “generic” container:
1#include "mem.h"
2#include "strings.h"
3#include <string.h>
4
5#define LIST_DEFAULT_SIZE 8
6#define LIST_BLOCK_COUNT 24
7
8#define LIST_TYPE(TYPE) \
9 typedef struct { \
10 TYPE **blocks; \
11 size_t len; \
12 size_t type_size; \
13 } LIST_##TYPE
14
15#define LIST_new(TYPE) \
16 ({ \
17 LIST_##TYPE l = {0}; \
18 l.type_size = sizeof(TYPE); \
19 l; \
20 })These macros are then used to define and create a list via:
1LIST_TYPE(char) cl = LIST_new(char);Now there is the need for interacting with the list, for this we need append, get and insert (plus their non bounds checking equivalents), allowing for:
1Allocator *a = bump_init(1024, 0);
2LIST_TYPE(char);
3LIST_char cl = LIST_new(char);
4LIST_append(&cl, a, 'H')
5LIST_append(&cl, a, 'E')
6LIST_append(&cl, a, 'L')
7assert(LIST_get(&cl, 0) == 'H')
8assert(LIST_get(&cl, 1) == 'E')
9assert(LIST_get(&cl, 2) == 'L')
10assert(LIST_insert_UNSAFE(&cl, 1, 'O'))
11assert(LIST_get_UNSAFE(&cl, 1) == 'O')All of these macros require the index into the block and the block itself.
ListIdx and idx_to_block_idx do exactly that:
1struct ListIdx {
2 // which block to use for the indexing
3 size_t block;
4 // the idx into said block
5 size_t block_idx;
6};
7
8struct ListIdx idx_to_block_idx(size_t idx);The implementation of idx_to_block_idx works in constant time and is
therefore a bit worse to read than one working in linear time due to the
exploitation of the geometric series, it does however follow
Indexing, just with a few changes to omit heavy computations
(\(\log_2\), etc.).
1inline __attribute__((always_inline, hot)) struct ListIdx idx_to_block_idx(size_t idx) {
2 if (idx < LIST_DEFAULT_SIZE) {
3 return (struct ListIdx){.block_idx = idx, .block = 0};
4 }
5
6 size_t adjusted = idx + LIST_DEFAULT_SIZE;
7 size_t msb_pos = 63 - __builtin_clzll(adjusted);
8
9 // This optimizes the block index lookup to be constant time
10 //
11 // block 0 size = LIST_DEFAULT_SIZE
12 // block 1 size = LIST_DEFAULT_SIZE*2
13 // block 2 size = LIST_DEFAULT_SIZE*4
14 // block 3 size = LIST_DEFAULT_SIZE*8
15 //
16 // The starting index of each block is a geometric series:
17 //
18 // s(i) = LIST_DEFAULT_SIZE * (2^i - 1)
19 //
20 // We solve for i, so the following stands:
21 //
22 // s(i) <= idx < s(i+1)
23 //
24 // 2^i - 1 <= idx / LIST_DEFAULT_SIZE < 2^(i+1) - 1
25 // idx / LIST_DEFAULT_SIZE + 1 >= 2^i
26 //
27 // Thus: adding LIST_DEFAULT_SIZE to idx shifts the series so the msb of idx +
28 // LIST_DEFAULT_SIZE correspond to the block number
29 //
30 // Visually:
31 //
32 // Global index: 0 1 2 3 4 5 6 7 | 8 9 10 ... 23 | 24 25 ... 55 | 56
33 // ... Block: 0 | 1 | 2 | 3 ...
34 // Block size: 8 | 16 | 32 | 64
35 // ... idx + LIST_DEFAULT_SIZE: 0+8=8 -> MSB pos 3 -> block 0 7+8=15 ->
36 // MSB pos 3 -> block 0 8+8=16 -> MSB pos 4 -> block 1 23+8=31-> MSB pos 4
37 // -> block 1 24+8=32-> MSB pos 5 -> block 2
38
39 // shifting the geometric series so 2^i aligns with idx
40
41 // log2(LIST_DEFAULT_SIZE) = 3 for LIST_DEFAULT_SIZE = 8
42#define LOG2_OF_LIST_DEFAULT_SIZE 3
43 // first block is LIST_DEFAULT_SIZE wide, this normalizes
44 size_t block = msb_pos - LOG2_OF_LIST_DEFAULT_SIZE;
45 size_t start_index_of_block =
46 (LIST_DEFAULT_SIZE << block) - LIST_DEFAULT_SIZE;
47 size_t block_idx = idx - start_index_of_block;
48
49 return (struct ListIdx){.block_idx = block_idx, .block = block};
50}LIST_append allocates on demand, based on the segment computed by
idx_to_block_idx:
1#define LIST_append(LIST, ALLOC, ELEM) \
2 { \
3 /* allocate block array if not yet allocated */ \
4 if ((LIST)->blocks == NULL) { \
5 (LIST)->blocks = \
6 CALL(ALLOC, request, LIST_BLOCK_COUNT * sizeof(void *)); \
7 ASSERT((LIST)->blocks != NULL, \
8 "LIST_append: block array allocation failed"); \
9 } \
10 \
11 struct ListIdx bi = idx_to_block_idx((LIST)->len); \
12 \
13 /* allocate the specific block if needed */ \
14 if ((LIST)->blocks[bi.block] == NULL) { \
15 uint64_t block_size = LIST_DEFAULT_SIZE << bi.block; \
16 (LIST)->blocks[bi.block] = \
17 CALL(ALLOC, request, block_size * (LIST)->type_size); \
18 ASSERT((LIST)->blocks[bi.block] != NULL, \
19 "LIST_append: block allocation failed"); \
20 } \
21 \
22 (LIST)->blocks[bi.block][bi.block_idx] = (ELEM); \
23 (LIST)->len++; \
24 }The non allocating interactions like _get, _get_UNSAFE and _insert_UNSAFE
do a bounds check if applicable and afterwards use the segment and the offset
computed by idx_to_block_idx:
1#define LIST_get(LIST, IDX) \
2 ({ \
3 ASSERT(IDX < (LIST)->len, "List_get out of bounds"); \
4 struct ListIdx b_idx = idx_to_block_idx(IDX); \
5 (LIST)->blocks[b_idx.block][b_idx.block_idx]; \
6 })
7
8#define LIST_get_UNSAFE(LIST, IDX) \
9 ({ \
10 struct ListIdx b_idx = idx_to_block_idx(IDX); \
11 (LIST)->blocks[b_idx.block][b_idx.block_idx]; \
12 })
13
14#define LIST_insert_UNSAFE(LIST, IDX, VAL) \
15 { \
16 struct ListIdx __idx = idx_to_block_idx(IDX); \
17 (LIST)->blocks[__idx.block][__idx.block_idx] = VAL; \
18 }Rust Implementation
“If you wish to make an apple pie from scratch, you must first invent the universe.”
-Carl Sagan
In this fashion we will:
- Implement mmap and munmap in assembly using the x86 Linux syscall ABI
- Implement a
std::alloc::GlobalAlloccompatible allocator based on that - Implement the segmented list using the allocator
- Profit.
Handrolling x86 mmap & munmap syscalls
About using the libc crate: This would be against my mentality of not using
dependencies if possible and libc is a large one due to it pulling in the C
runtime for two syscalls I can just wrap myself using
asm!.
Of course the above is only correct on Linux
#[no_std]since in some cases Rusts std depends on libc, but you get what I’m trying to convey.
My first step was porting their arguments into the Rust type system. I couldn’t
use rust enums, since they require variants to be exclusive, which the bit
flags for READ, WRITE, … and PRIVATE, ANONYMOUS, … aren’t. So i had
to settle for a struct containing i32. To support bit or(ed) flags for the
arguments I also had to quickly implement std::ops::BitOr:
1//! constants taken from https://github.com/openbsd/src/blob/master/sys/sys/mman.h
2#[cfg(target_os = "openbsd")]
3const MMAP_SYSCALL: i64 = 197;
4#[cfg(target_os = "openbsd")]
5const MUNMAP_SYSCALL: i64 = 73;
6
7#[cfg(target_os = "linux")]
8const MMAP_SYSCALL: i64 = 9;
9#[cfg(target_os = "linux")]
10const MUNMAP_SYSCALL: i64 = 11;
11
12// Not an enum, since NONE, READ, WRITE and EXEC aren't mutually exclusive
13pub struct MmapProt(i32);
14impl MmapProt {
15 /// no permissions
16 pub const NONE: MmapProt = MmapProt(0x00);
17 /// pages can be read
18 pub const READ: MmapProt = MmapProt(0x01);
19 /// pages can be written
20 pub const WRITE: MmapProt = MmapProt(0x02);
21 /// pages can be executed
22 pub const EXEC: MmapProt = MmapProt(0x04);
23 pub fn bits(self) -> i32 {
24 self.0
25 }
26}
27
28impl std::ops::BitOr for MmapProt {
29 type Output = Self;
30 fn bitor(self, rhs: Self) -> Self::Output {
31 MmapProt(self.0 | rhs.0)
32 }
33}
34
35pub struct MmapFlags(i32);
36
37impl MmapFlags {
38 /// share changes
39 pub const SHARED: MmapFlags = MmapFlags(0x0001);
40 /// changes are private
41 pub const PRIVATE: MmapFlags = MmapFlags(0x0002);
42 /// map addr must be exactly as requested
43 pub const FIXED: MmapFlags = MmapFlags(0x0010);
44
45 /// fail if address not available
46 #[cfg(target_os = "openbsd")]
47 pub const NOREPLACE: MmapFlags = MmapFlags(0x0800); // __MAP_NOREPLACE
48 #[cfg(target_os = "linux")]
49 pub const NOREPLACE: MmapFlags = MmapFlags(0x100000); // MAP_FIXED_NOREPLACE (Linux ≥ 5.4)
50
51 /// allocated from memory, swap space
52 #[cfg(target_os = "openbsd")]
53 pub const ANONYMOUS: MmapFlags = MmapFlags(0x1000);
54 /// allocated from memory, swap space
55 #[cfg(target_os = "linux")]
56 pub const ANONYMOUS: MmapFlags = MmapFlags(0x20);
57
58 /// mapping is used for stack
59 pub const STACK: MmapFlags = MmapFlags(0x4000);
60
61 /// omit from dumps
62 pub const CONCEAL: MmapFlags = MmapFlags(0x8000);
63
64 // OpenBSD-only: avoid faulting in pages initially
65 #[cfg(target_os = "openbsd")]
66 pub const NOFAULT: MmapFlags = MmapFlags(0x2000);
67 pub fn bits(self) -> i32 {
68 self.0
69 }
70}The functions themselves are pretty straightforward if you have ever called a
syscall from assembly. We use the syscall instruction and fill some registers
with the arguments according to the x86 Linux syscall
ABI:
| Registers | Value |
|---|---|
rax | Syscall kind (9 for mmap) |
rdi | pointer or null for anonymous (Option::None for the latter) |
rsi | region length |
rdx | protection modifiers |
r10 | flags |
r8 | file descriptor (-1 for anonymous) |
r9 | offset |
The only thing tripping me up were the possible values for options and
lateout, since these weren’t obvious to me. After a lot of searching I found
some
docs:
| Option | Dacription |
|---|---|
nostack | asm does not modify the stack via push, pop or red-zone |
lateout
writes the register contents to its argument and doesn’t care about overwriting
inputs. The std::ptr::NonNull return type is applicable, since mmap can only
return valid non-null memory, otherwise the rax would return MMAP_FAILED
((void *) -1 in Rust simply -1). I only use nostack, since we don’t
fiddle with the stack. Other options like readonly or preserves_flags
aren’t applicable, since syscall writes to rax and modifies RFLAGS
1#[inline(always)]
2pub fn mmap(
3 ptr: Option<std::ptr::NonNull<u8>>,
4 length: usize,
5 prot: MmapProt,
6 flags: MmapFlags,
7 fd: i32,
8 offset: i64,
9) -> std::ptr::NonNull<u8> {
10 let ret: isize;
11
12 unsafe {
13 core::arch::asm!(
14 "syscall",
15 in("rax") MMAP_SYSCALL,
16 in("rdi") ptr.map(|nn| nn.as_ptr()).unwrap_or(std::ptr::null_mut()),
17 in("rsi") length,
18 in("rdx") prot.bits(),
19 in("r10") flags.bits(),
20 in("r8") fd,
21 in("r9") offset,
22 lateout("rax") ret,
23 clobber_abi("sysv64"),
24 options(nostack)
25 );
26 }
27 if ret < 0 {
28 let errno = -ret;
29 eprintln!(
30 "mmap failed (errno {}): {}",
31 errno,
32 std::io::Error::from_raw_os_error(errno as i32)
33 );
34 std::process::abort()
35 }
36
37 unsafe { std::ptr::NonNull::new_unchecked(ret as *mut u8) }
38}Unmapping is easier than mmap, since it only requires a pointer to the mapped
region in rdi and its size in rsi. We again use rax to check if the
kernel complained about our syscall parameters.
1#[inline(always)]
2pub fn munmap(ptr: std::ptr::NonNull<u8>, size: usize) {
3 let ret: isize;
4 unsafe {
5 core::arch::asm!(
6 "syscall",
7 in("rax") MUNMAP_SYSCALL,
8 in("rdi") ptr.as_ptr(),
9 in("rsi") size,
10 lateout("rax") ret,
11 clobber_abi("sysv64"),
12 options(nostack)
13 );
14 }
15
16 if ret < 0 {
17 let errno = -ret;
18 eprintln!(
19 "munmap failed (errno {}): {}",
20 errno,
21 std::io::Error::from_raw_os_error(errno as i32)
22 );
23 std::process::abort()
24 }
25}Bump allocator
The bump allocator now uses these safe syscall wrappers to allocate and
deallocate memory chunks, it also implements std::alloc::GlobalAlloc and
needs to implement Send and Sync since its used via #[global_allocator],
which is static and requires the corresponding traits.
The main component of the allocator is its metadata - SegmentedAllocCtx:
1const MIN_SIZE: usize = 4096;
2const MAX_BLOCKS: usize = 55;
3const GROWTH: usize = 2;
4
5#[derive(Debug)]
6struct SegmentedAllocCtx {
7 /// idx into self.blocks
8 cur_block: usize,
9 /// size of the current block
10 size: usize,
11 /// bytes in use of the current block
12 pos: usize,
13 blocks: [Option<NonNull<u8>>; MAX_BLOCKS],
14 block_sizes: [usize; MAX_BLOCKS],
15}
16
17impl SegmentedAllocCtx {
18 const fn new() -> Self {
19 SegmentedAllocCtx {
20 size: MIN_SIZE,
21 cur_block: 0,
22 pos: 0,
23 blocks: [const { None }; MAX_BLOCKS],
24 block_sizes: [0; MAX_BLOCKS],
25 }
26 }
27}Since I don’t care about thread safety and this is just a comparison between my
already thread unsafe C code, this context is wrapped in an UnsafeCell:
1/// Implements a variable size bump allocator, employing mmap to allocate a starting block of
2/// 4096B, once a block is exceeded by a request, the allocator mmaps a new block double the size
3/// of the previously allocated block
4pub struct SegmentedAlloc {
5 ctx: UnsafeCell<SegmentedAllocCtx>,
6}To cement this unsafeness, Sync and Send are implemented as nops, this also
requires never using SegmentedAlloc in multithreaded contexts.
1unsafe impl Send for SegmentedAlloc {}
2unsafe impl Sync for SegmentedAlloc {}I ported the bump allocator line by line to rust. It uses the mmap and
munmap wrappers, keeps track of its state via SegmentedAllocCtx and hands
out data via SegmentedAlloc::request. SegmentedAlloc::free is the basis for
implementing Drop for SegmentedList which will come in the next section.
1#[inline(always)]
2fn align_up(val: usize, align: usize) -> usize {
3 (val + align - 1) & !(align - 1)
4}
5
6impl SegmentedAlloc {
7 pub const fn new() -> Self {
8 Self {
9 ctx: UnsafeCell::new(SegmentedAllocCtx::new()),
10 }
11 }
12
13 pub fn request(&self, layout: std::alloc::Layout) -> NonNull<u8> {
14 assert!(layout.size() > 0, "Zero-size allocation is not allowed");
15
16 let ctx = unsafe { &mut *self.ctx.get() };
17
18 if ctx.blocks[0].is_none() {
19 ctx.size = MIN_SIZE;
20 ctx.cur_block = 0;
21 ctx.pos = 0;
22 ctx.block_sizes[0] = MIN_SIZE;
23 ctx.blocks[0] = Some(mmap(
24 None,
25 MIN_SIZE,
26 mmap::MmapProt::READ | mmap::MmapProt::WRITE,
27 mmap::MmapFlags::PRIVATE | mmap::MmapFlags::ANONYMOUS,
28 -1,
29 0,
30 ));
31 }
32
33 loop {
34 let block_capacity = ctx.block_sizes[ctx.cur_block];
35 debug_assert!(
36 block_capacity >= ctx.size,
37 "block_capacity should be >= ctx.size"
38 );
39
40 let offset = align_up(ctx.pos, layout.align());
41 let end_offset = offset
42 .checked_add(layout.size())
43 .expect("Allocation size overflow");
44
45 if end_offset >= block_capacity {
46 assert!(ctx.cur_block + 1 < MAX_BLOCKS, "Exceeded MAX_BLOCKS");
47 let new_size = ctx.size * GROWTH;
48 ctx.cur_block += 1;
49 ctx.block_sizes[ctx.cur_block] = new_size;
50 ctx.size = new_size;
51 ctx.pos = 0;
52 ctx.blocks[ctx.cur_block] = Some(mmap(
53 None,
54 new_size,
55 mmap::MmapProt::READ | mmap::MmapProt::WRITE,
56 mmap::MmapFlags::PRIVATE | mmap::MmapFlags::ANONYMOUS,
57 -1,
58 0,
59 ));
60 continue;
61 }
62
63 let block_ptr = ctx.blocks[ctx.cur_block].unwrap();
64
65 let ptr_addr = unsafe { block_ptr.as_ptr().add(offset) };
66 debug_assert!(
67 (ptr_addr as usize) % layout.align() == 0,
68 "Returned pointer is not aligned to {}",
69 layout.align()
70 );
71
72 ctx.pos = end_offset;
73
74 return NonNull::new(ptr_addr)
75 .expect("Failed to create NonNull from allocation pointer");
76 }
77 }
78
79 pub fn free(&mut self) {
80 let ctx = unsafe { &mut *self.ctx.get() };
81 for i in 0..MAX_BLOCKS {
82 let size = ctx.block_sizes[i];
83 if size == 0 {
84 break;
85 }
86
87 let Some(block) = ctx.blocks[i] else {
88 break;
89 };
90 munmap(block, size);
91 }
92 }
93}std::alloc::GlobalAlloc is just an abstraction to calling
SegmentedAlloc::request on alloc and nop on dealloc:
1unsafe impl GlobalAlloc for SegmentedAlloc {
2 unsafe fn alloc(&self, layout: std::alloc::Layout) -> *mut u8 {
3 self.request(layout).as_ptr()
4 }
5 unsafe fn dealloc(&self, _ptr: *mut u8, _layout: std::alloc::Layout) {}
6}We can now use the following to make our complete program use the allocator:
1use segmented_rs::alloc;
2
3#[global_allocator]
4static A: alloc::SegmentedAlloc = alloc::SegmentedAlloc::new();Or we inject the allocator into our list to only make it use the allocator.
Segmented List
As introduced in Segmented Lists vs Dynamic
Arrays, a segmented list consists of
segments. Each segment is lazily allocated and doubles in size to the previous
one. The first segment is of size 8, the next 16, the next 32, and so on.
Keeping track of these sizes and the starting point is crucial for indexing.
1// 24 blocks means around 134mio elements, thats enough I think
2pub const BLOCK_COUNT: usize = 24;
3pub const START_SIZE: usize = 8;
4pub const BLOCK_STARTS: [usize; BLOCK_COUNT] = {
5 let mut arr = [0usize; BLOCK_COUNT];
6 let mut i = 0;
7 while i < BLOCK_COUNT {
8 arr[i] = START_SIZE * ((1 << i) - 1);
9 i += 1;
10 }
11 arr
12};
13
14/// SegmentedIdx represents a cached index lookup into the segmented list, computed with
15/// `SegmentedList::compute_segmented_idx`, can be used with `SegmentedList::get_with_segmented_idx`
16/// and `SegmentedList::get_mut_with_segmented_idx`.
17///
18/// Primary usecase is to cache the lookup of many idxes, thus omiting the lookup computation which
19/// can be too heavy in intensive workloads.
20#[derive(Copy, Clone)]
21struct SegmentedIdx(usize, usize);
22
23/// SegmentedList is a drop in `std::vec::Vec` replacement providing zero cost growing and stable
24/// pointers even after grow with `::push`.
25///
26/// The list is implemented by chaining blocks of memory to store its elements. Each block is
27/// allocated on demand when an index falls into it (for instance during appends), starting at
28/// `START_SIZE` elements in the first block and doubling the block size for each subsequent
29/// allocation. This continues until `BLOCK_COUNT` is reached. Existing blocks are never moved or
30/// reallocated, so references into the list remain valid across growth operations.
31///
32/// This makes the SegmentedList an adequate replacement for `std::vec::Vec` when dealing with
33/// heavy and unpredictable growth workloads due the omission of copy/move overhead on expansion.
34pub struct SegmentedList<T> {
35 blocks: [*mut std::mem::MaybeUninit<T>; BLOCK_COUNT],
36 block_lengths: [usize; BLOCK_COUNT],
37 allocator: SegmentedAlloc,
38 cur_block: usize,
39 offset_in_block: usize,
40 len: usize,
41}SegmentedList holds an array of segments (blocks), an array of their
lengths (block_lengths), the allocator used to do any allocation and the
count of the currently contained elements, overarching all segments - len.
The main logic for indexing is encoded in the SegmentedIdx(segment, offset)
struct and its producer: idx_to_block_idx.
1impl <T> SegmentedList<T> {
2
3 // [...]
4
5 #[inline(always)]
6 fn idx_to_block_idx(&self, idx: usize) -> SegmentedIdx {
7 if idx < START_SIZE {
8 return SegmentedIdx(0, idx);
9 }
10 let adjusted = idx + START_SIZE;
11 let msb_pos = core::mem::size_of::<usize>() * 8 - 1 - adjusted.leading_zeros() as usize;
12 let block = msb_pos - (START_SIZE.trailing_zeros() as usize);
13 SegmentedIdx(block, idx - BLOCK_STARTS[block])
14 }
15
16 // [...]
17
18}In comparison to the C implementation, the Rust one doesnt lazy allocate the
first chunk, but eagerly allocates its first segment in Self::new (I don’t
remember why I did that):
1impl <T> SegmentedList<T> {
2 pub fn new() -> Self {
3 let mut s = Self {
4 blocks: [std::ptr::null_mut(); BLOCK_COUNT],
5 block_lengths: [0; BLOCK_COUNT],
6 allocator: SegmentedAlloc::new(),
7 cur_block: 0,
8 len: 0,
9 offset_in_block: 0,
10 };
11
12 let element_count = START_SIZE;
13 let as_bytes = element_count * size_of::<T>();
14 s.blocks[0] = s
15 .allocator
16 .request(Layout::from_size_align(as_bytes, align_of::<T>()).unwrap())
17 .as_ptr() as *mut MaybeUninit<T>;
18 s.block_lengths[0] = element_count;
19 s
20 }
21
22 // [...]
23
24}Allocating a new segment (Self::alloc_block) outside of Self::new happens
when the current segment is out of space in any appending method, for instance
Self::push(T):
1impl <T> SegmentedList<T> {
2 // [...]
3
4 #[inline(always)]
5 fn alloc_block(&mut self, block: usize) {
6 use std::alloc::Layout;
7 use std::mem::{MaybeUninit, align_of, size_of};
8
9 let elems = START_SIZE << block;
10 let bytes = elems * size_of::<T>();
11 let layout = Layout::from_size_align(bytes, align_of::<T>())
12 .expect("Invalid layout for SegmentedList block");
13
14 let ptr = self.allocator.request(layout).as_ptr() as *mut MaybeUninit<T>;
15 debug_assert!(!ptr.is_null(), "SegmentedAlloc returned null");
16
17 self.blocks[block] = ptr;
18 self.block_lengths[block] = elems;
19 }
20
21 pub fn push(&mut self, v: T) {
22 if self.block_lengths[self.cur_block] == 0 {
23 self.alloc_block(self.cur_block);
24 }
25
26 unsafe {
27 (*self.blocks[self.cur_block].add(self.offset_in_block)).write(v);
28 }
29
30 self.len += 1;
31 self.offset_in_block += 1;
32
33 if self.offset_in_block == self.block_lengths[self.cur_block] {
34 self.cur_block += 1;
35 self.offset_in_block = 0;
36 }
37 }
38
39 pub fn get(&self, idx: usize) -> Option<&T> {
40 if idx >= self.len {
41 return None;
42 }
43 let SegmentedIdx(block, block_index) = self.idx_to_block_idx(idx);
44 Some(unsafe { (*self.blocks[block].add(block_index)).assume_init_ref() })
45 }
46
47 // [...]
48}Since I want to provide somewhat of a std::vec::Vec drop in replacement, I
added a truckload of methods vec also supports. Due to the already way too
large nature of this article I’ll restrict myself to to_vec, capacity,
clear and impl<T: Clone + Copy> Clone for SegmentedList<T>, since these
are somewhat non-trivial:
1impl<T> SegmentedList<T> {
2 /// Collects self and its contents into a vec
3 pub fn to_vec(mut self) -> Vec<T> {
4 let mut result = Vec::with_capacity(self.len);
5 let mut remaining = self.len;
6
7 for block_idx in 0..BLOCK_COUNT {
8 if remaining == 0 {
9 break;
10 }
11
12 let len = self.block_lengths[block_idx];
13 if len == 0 {
14 break;
15 }
16
17 let ptr = self.blocks[block_idx];
18 let take = remaining.min(len);
19 for i in 0..take {
20 let value = unsafe { (*ptr.add(i)).assume_init_read() };
21 result.push(value);
22 }
23 remaining -= take;
24 // We "forget" the block, no dealloc, bump allocator manages memory
25 self.blocks[block_idx] = std::ptr::null_mut();
26 }
27 result
28 }
29
30 pub fn capacity(&self) -> usize {
31 self.block_lengths.iter().copied().sum()
32 }
33
34 pub fn clear(&mut self) {
35 let mut remaining = self.len;
36 for block_idx in 0..BLOCK_COUNT {
37 if remaining == 0 {
38 break;
39 }
40 let len = self.block_lengths[block_idx];
41 let ptr = self.blocks[block_idx];
42 if len == 0 {
43 break;
44 }
45 let take = remaining.min(len);
46 for i in 0..take {
47 unsafe { (*ptr.add(i)).assume_init_drop() };
48 }
49 remaining -= take;
50 }
51 self.len = 0;
52 }
53}
54
55impl<T: Clone + Copy> Clone for SegmentedList<T> {
56 fn clone(&self) -> Self {
57 let mut new_list = SegmentedList::new();
58 new_list.len = self.len;
59
60 for block_idx in 0..BLOCK_COUNT {
61 if self.block_lengths[block_idx] == 0 {
62 break;
63 }
64 let src_ptr = self.blocks[block_idx];
65 let elems = self.block_lengths[block_idx];
66 if elems == 0 {
67 continue;
68 }
69 new_list.alloc_block(block_idx);
70 let dst_ptr = new_list.blocks[block_idx];
71
72 for i in 0..elems {
73 unsafe {
74 let val = (*src_ptr.add(i)).assume_init();
75 (*dst_ptr.add(i)).write(val);
76 }
77 }
78 new_list.block_lengths[block_idx] = elems;
79 }
80
81 new_list
82 }
83}The attentive reader will have noticed I snuck some small optimisations in:
- Inline
alloc_block,idx_to_block_idx(-2% runtime) - Inline
mmapandmunmap(-4% runtime) - precompute block boundaries in
BLOCK_STARTS(-41% runtime) - cache
SegmentedIdxcomputation forSelf::pushviacur_blockandoffset_in_block - remove unnecessary indirections (-8% runtime)
segmented_rs::list::SegmentedList vs std::vec::Vec
Benchmarks are of course done with criterion:
1// benches/list.rs
2use criterion::{BatchSize, Criterion, black_box, criterion_group, criterion_main};
3use segmented_rs::list::SegmentedList;
4
5pub fn bench_segmented_list(c: &mut Criterion) {
6 fn bench_push<T: Clone>(c: &mut Criterion, name: &str, template: T, count: usize) {
7 c.bench_function(name, |b| {
8 b.iter_batched(
9 || SegmentedList::new(),
10 |mut list| {
11 for _ in 0..count {
12 list.push(black_box(template.clone()));
13 }
14 black_box(list)
15 },
16 BatchSize::SmallInput,
17 )
18 });
19 }
20
21 bench_push(c, "segmented_list_push_u64", 123u64, 10_000);
22
23 #[derive(Clone)]
24 struct MediumElem([u8; 40]);
25 bench_push(c, "segmented_list_push_medium", MediumElem([42; 40]), 1_000);
26
27 #[derive(Clone)]
28 struct HeavyElem(Box<[u8]>);
29 bench_push(
30 c,
31 "segmented_list_push_heavy_1MiB",
32 HeavyElem(vec![161u8; 1 * 1024 * 1024].into_boxed_slice()),
33 50,
34 );
35}
36
37criterion_group!(benches, bench_segmented_list);
38criterion_main!(benches);The same for std::vec::Vec:
1// benches/vec.rs
2use criterion::{BatchSize, Criterion, black_box, criterion_group, criterion_main};
3
4pub fn bench_vec(c: &mut Criterion) {
5 fn bench_push<T: Clone>(c: &mut Criterion, name: &str, template: T, count: usize) {
6 c.bench_function(name, |b| {
7 b.iter_batched(
8 || Vec::new(),
9 |mut vec| {
10 for _ in 0..count {
11 vec.push(black_box(template.clone()));
12 }
13 black_box(vec)
14 },
15 BatchSize::SmallInput,
16 )
17 });
18 }
19
20 bench_push(c, "vec_push_u64", 123u64, 10_000);
21
22 #[derive(Clone)]
23 struct MediumElem([u8; 40]);
24 bench_push(c, "vec_push_medium", MediumElem([42; 40]), 1_000);
25
26 #[derive(Clone)]
27 struct HeavyElem(Box<[u8]>);
28 bench_push(
29 c,
30 "vec_push_heavy_1MiB",
31 HeavyElem(vec![161u8; 1 * 1024 * 1024].into_boxed_slice()),
32 50,
33 );
34}
35
36criterion_group!(benches, bench_vec);
37criterion_main!(benches);Both are runnable via cargo bench --bench list:
1segmented_list_push_u64 time: [39.502 µs 40.156 µs 40.860 µs]
2segmented_list_push_medium time: [35.512 µs 35.901 µs 36.306 µs]
3segmented_list_push_heavy_1MiB time: [3.0590 ms 3.0932 ms 3.1345 ms]
4segmented_list_push_heavy_10MiB time: [3.3591 ms 3.3934 ms 3.4299 ms]
5segmented_list_push_heavy_50MiB time: [19.895 ms 20.425 ms 21.353 ms]and cargo bench --bench vec:
1vec_push_u64 time: [32.955 µs 33.463 µs 33.961 µs]
2vec_push_medium time: [28.725 µs 29.058 µs 29.435 µs]
3vec_push_heavy_1MiB time: [3.3439 ms 3.3816 ms 3.4236 ms]
4vec_push_heavy_10MiB time: [3.7747 ms 3.8124 ms 3.8548 ms]
5vec_push_heavy_50MiB time: [21.718 ms 21.865 ms 22.018 ms]So it beats vec on larger elements (starting from 1MiB), but these are only
applicable when moving large amounts of giant blobs. The rust team did a great
job at optimising std::vec::Vec, my “naive” implementation comes near, but
only outperforms on very large workloads.
Rust Pain Points
Sync and Send have to be implemented for
std::alloc::GlobalAlloc, I get the allocator has to be shared between threads, but its weird to have a nop implcargo testexecutes tests concurrently and therefore crash if not run with--test-threads=1, which was fucking hard to debug, since these are flaky as hell, sometimes it happens, sometimes it doesnt:illegal memory access:
TEXT1running 24 tests 2error: test failed, to rerun pass `--lib` 3 4Caused by: 5 process didn't exit successfully: 6 `/home/teo/programming/segmented-rs/target/debug/deps/segmented_rs-68ce766f62589be2` 7 (signal: 11, SIGSEGV: invalid memory reference)SendErrorsinceSegmentedAlloccouldn’t be send from a thread to anotherTEXT1thread 'main' panicked at library/test/src/lib.rs:463:73: 2called `Option::unwrap()` on a `None` value 3[Thread 0x7ffff691f6c0 (LWP 22634) exited] 4 5thread 'list::tests::stress_test_large_fill' panicked at library/test/src/lib.rs:686:30: 6called `Result::unwrap()` on an `Err` value: SendError { .. }
Segfaults in Rust are worse to debug with
gdbthan in C, unaligned memory issues, segfaults and other invalid memory access are hard to pinpointNo stack traces for
panic!when implementingstd::alloc::GlobalAlloc, just:TEXT1panic:Gdb (most of the time) helps with the stacktrace when compiling with
RUSTFLAGS="-C debuginfo=2".
What Rust does better than C (at least in this case)
Generics, looking at you
_Generic, Rust just did it better. To be fair, even Java did it better. What even is this:C1#define DBG(EXPR) //... 2({ 3 _Pragma("GCC diagnostic push") 4 _Pragma("GCC diagnostic ignored \"-Wformat\"") __auto_type _val = (EXPR); 5 fprintf(stderr, "[%s:%d] %s = ", __FILE__, __LINE__, #EXPR); 6 _Generic((_val), 7 int: fprintf(stderr, "%d\n", _val), 8 long: fprintf(stderr, "%ld\n", _val), 9 long long: fprintf(stderr, "%lld\n", _val), 10 unsigned: fprintf(stderr, "%u\n", _val), 11 unsigned long: fprintf(stderr, "%lu\n", _val), 12 unsigned long long: fprintf(stderr, "%llu\n", _val), 13 float: fprintf(stderr, "%f\n", _val), 14 double: fprintf(stderr, "%f\n", _val), 15 const char *: fprintf(stderr, "\"%s\"\n", _val), 16 char *: fprintf(stderr, "\"%s\"\n", _val), 17 default: fprintf(stderr, "<unprintable>\n")); 18 _Pragma("GCC diagnostic pop") _val; 19})There isn’t even a way to run different functions for differing datatypes, since each path has to compile and you can’t pass something like a double to
strleneven if this isn’t really happening, gcc still complains, see Workarounds for C11 _Generic.Drop implementations and traits in general are so much better than any C alternative, even though I can think of at least 3 shittier ways to emulate traits in C
Enums are so much fun in Rust, I love variant “bodies”? The only thing tripping me up was that one can’t use them to mirror the C flag behaviour for bitOring arguments.
Builtin testing and benchmarking (the latter at least somewhat). I really miss Gos testing behaviour in Rust, but the default “workflow” is fine for my needs (table driven tests for the win)
Compile time constructs, precomputing the starts of blocks allowed me to simplify my segment and offset lookup code by a whole lot, and its faster
Of course this comparison isn’t that fair, since C is from the 70s and Rust has
learned from the shortcomings of the systems level programming languages coming
before it. I still like to program in C, particulary for the challenge and the
level of control it allows, but only with -fsanitize=address,undefined and
running valgrind a whole lot.